本帖最后由 kay2kay 于 2021-03-14 23:14 编辑
结构体C语言中的结构体是一种自定义的数据类型,一个结构体里可由其它各种类型组合而成
声明结构体举个简单的例子,自定义一个为player的类型,如下: struct Player{
float hp; //人物血量
float mp; //人物魔量
int money; //人物金钱
int atk; //人物攻击力
char name[20]; //人物昵称
float x; //人物x坐标
float y; //人物y坐标
};
结构体的初始化初始化使用自定义的结构体,然后初始化 #include "stdafx.h"
#include <string.h>
struct Player{
float hp; //人物血量
float mp; //人物魔力值
int money; //人物金钱
int atk; //人物攻击力
char name[10]; //人物昵称
float x; //人物x坐标
float y; //人物y坐标
};
int main(int argc, char* argv[])
{
Player player;
player.hp=100;
player.mp=50;
player.money=1000;
player.atk=10;
strcpy(player.name,"lyl610abc");
player.x=600;
player.y=100;
return 0;
}
对应汇编代码21: Player player;
22:
23: player.hp=100;
00401028 mov dword ptr [ebp-24h],42C80000h
24: player.mp=50;
0040102F mov dword ptr [ebp-20h],42480000h
25: player.money=1000;
00401036 mov dword ptr [ebp-1Ch],3E8h
26: player.atk=10;
0040103D mov dword ptr [ebp-18h],0Ah
27: strcpy(player.name,"lyl610abc");
00401044 push offset string "lyl610abc" (0042601c)
00401049 lea eax,[ebp-14h]
0040104C push eax
0040104D call strcpy (00401090)
00401052 add esp,8
28: player.x=600;
00401055 mov dword ptr [ebp-8],44160000h
29: player.y=100;
0040105C mov dword ptr [ebp-4],42C80000h
| 结构体成员 | 含义 | 对应地址 | 占用空间(单位字节) |
|---|
| hp | 血量 | ebp-24h | 4 | | mp | 魔力值 | ebp-20h | 4 | | money | 金钱 | ebp-1Ch | 4 | | atk | 攻击 | ebp-18h | 4 | | name | 昵称 | ebp-14h | 12 | | x | x坐标 | ebp-8 | 4 | | y | y坐标 | ebp-4 | 4 |
不难看出结构体的成员的存储和数组并无差别,依旧是从低地址开始连续存储 其中要注意到,name成员实际占用空间为12字节,比声明的char name[10],多了2字节,为内存对齐的结果 结构体作为参数传递参数传递#include "stdafx.h"
#include <string.h>
struct Player{
float hp; //人物血量
float mp; //人物魔量
int money; //人物金钱
int atk; //人物攻击力
char name[10]; //人物昵称
float x; //人物x坐标
float y; //人物y坐标
};
void getStruct(struct Player player){
}
int main(int argc, char* argv[])
{
Player player;
getStruct(player);
return 0;
}
对应汇编代码28: getStruct(player);
004106D8 sub esp,24h
004106DB mov ecx,9
004106E0 lea esi,[ebp-24h]
004106E3 mov edi,esp
004106E5 rep movs dword ptr [edi],dword ptr [esi]
004106E7 call @ILT+5(getStruct) (0040100a)
004106EC add esp,24h
分析流程1.提升堆栈24h(为结构体的大小) 004106D8 sub esp,24h
2.将9赋值给ecx(作为计数器使用,也就是要循环9次) 004106DB mov ecx,9
3.将结构体的首地址传址给esi 004106E0 lea esi,[ebp-24h]
4.将esp赋值给edi,也就是将栈顶地址赋给edi 004106E3 mov edi,esp
5.重复9次(重复直到ecx为0),将esi里的值赋值给edi里的值,每次ecx都会自减1,esi和edi自增4(增或减取决于DF标志位) 为什么是循环9次? 前面提升的堆栈为24h,对应十进制为36,这里每次循环都会让esi和edi自增4,36/4=9,所以要循环9次 004106E5 rep movs dword ptr [edi],dword ptr [esi]
结合前面的esi=结构体首地址,edi为栈顶,这行代码就是将结构体复制到堆栈中
6.调用以结构体为参数的函数 004106E7 call @ILT+5(getStruct) (0040100a)
7.函数调用结束后进行堆栈外平衡,将之前提升的堆栈恢复 004106EC add esp,24h
小总结通过前面的分析可以知道,将结构体作为参数来传递是将整个结构体赋值到堆栈中来进行传递的 结构体作为返回值传递返回值传递#include "stdafx.h"
#include <string.h>
struct Player{
float hp; //人物血量
float mp; //人物魔量
int money; //人物金钱
int atk; //人物攻击力
char name[10]; //人物昵称
float x; //人物x坐标
float y; //人物y坐标
};
Player retStruct(){
Player player;
return player;
}
int main(int argc, char* argv[])
{
Player player;
player=retStruct();
return 0;
}
对应汇编代码函数外部30: Player player;
31: player=retStruct();
0040107E lea eax,[ebp-6Ch]
00401081 push eax
00401082 call @ILT+0(retStruct) (00401005)
00401087 add esp,4
0040108A mov esi,eax
0040108C mov ecx,9
00401091 lea edi,[ebp-48h]
00401094 rep movs dword ptr [edi],dword ptr [esi]
00401096 mov ecx,9
0040109B lea esi,[ebp-48h]
0040109E lea edi,[ebp-24h]
004010A1 rep movs dword ptr [edi],dword ptr [esi]
可以看到,函数明明是个无参的函数,但是却在函数前push了eax,并且eax是ebp-6C的地址 为什么明明是无参函数,却仍然push了 eax? 这里的eax是作为返回值来使用的,要将整个结构体作为返回值来传递,只用一个eax肯定是不够存储的,数据应该存在堆栈中,而这里就是用eax来保存 要存储返回结构体的堆栈地址的
函数内部前面所说可能有些抽象,来结合函数里面返回的内容分析: 19: Player player;
20: return player;
00401038 mov ecx,9
0040103D lea esi,[ebp-24h]
00401040 mov edi,dword ptr [ebp+8]
00401043 rep movs dword ptr [edi],dword ptr [esi]
00401045 mov eax,dword ptr [ebp+8]
21: }
00401048 pop edi
00401049 pop esi
0040104A pop ebx
0040104B mov esp,ebp
0040104D pop ebp
0040104E ret
先看前面几行代码 00401038 mov ecx,9
0040103D lea esi,[ebp-24h]
00401040 mov edi,dword ptr [ebp+8]
00401043 rep movs dword ptr [edi],dword ptr [esi]
发现和前面将结构体作为参数传递的代码差不多,就是将结构体的数据复制到堆栈中,此时复制的堆栈的起始地址为ebp+8
再看关键语句 00401045 mov eax,dword ptr [ebp+8]
这里就是将ebp+8也就是前面复制的堆栈的起始位置 赋值给 eax,eax作为返回值来传递数据
剩下的内容就是恢复现场和返回,这里就不再过多赘述 返回后00401087 add esp,4
0040108A mov esi,eax
0040108C mov ecx,9
00401091 lea edi,[ebp-48h]
00401094 rep movs dword ptr [edi],dword ptr [esi]
00401096 mov ecx,9
0040109B lea esi,[ebp-48h]
0040109E lea edi,[ebp-24h]
004010A1 rep movs dword ptr [edi],dword ptr [esi]
返回后首先进行堆栈外平衡,因为先前push了一个eax 00401087 add esp,4
然后就是熟悉的操作 0040108A mov esi,eax
0040108C mov ecx,9
00401091 lea edi,[ebp-48h]
00401094 rep movs dword ptr [edi],dword ptr [esi]
00401096 mov ecx,9
0040109B lea esi,[ebp-48h]
0040109E lea edi,[ebp-24h]
004010A1 rep movs dword ptr [edi],dword ptr [esi]
先将eax这个返回值赋值给esi 然后就是把返回值复制到现在的堆栈中 再接着就是把堆栈中的数据复制给临时变量player,对应player=retStruct();
小总结将结构体作为返回值,会将返回值eax压入堆栈中,说明了push 的内容不一定是参数,也可以是返回值
内存对齐内存对齐也称作字节对齐 前面或多或少都有提到过内存对齐,但没有具体展开,现在来谈谈内存对齐 为什么要内存对齐性能原因寻址时提高效率,采用了以空间换时间的思想 当寻址的内存的单位和本机宽度一致时,寻址的效率最高 举个例子: - 在32位的机器上,一次读32位(4字节)的内存 效率最高
- 在64位的机器上,一次读64位(8字节)的内存 效率最高
平台原因(移植原因)不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常 内存对齐例子前面其实已经有过不少内存对齐的例子,就比如上面的 char name[10];
实际占用的空间为12,12=4 × 3 ,这里的4就是本机宽度,单位为字节,实际占用的空间为本机宽度的整数倍
再看看结构体的内存对齐: #include "stdafx.h"
#include <string.h>
struct S1{
char a;
int b;
char c;
};
struct S2{
int a;
char b;
char c;
};
int main(int argc, char* argv[])
{
S1 s1;
S2 s2;
printf("%d\n",sizeof(s1));
printf("%d\n",sizeof(s2));
return 0;
}
运行结果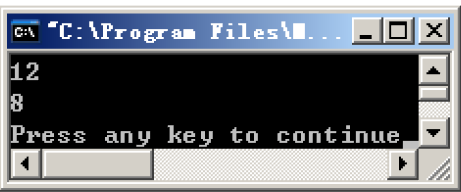
分析可与看到,明明结构体里的参数类型是一样的,都是两个char和一个int,但其占用的空间却不一样,这就是内存对齐的结果 此时的对齐参数为默认值8 | 结构体 | a占用空间\数据类型 | b用空间\数据类型 | c占用空间\数据类型 | 总占用空间 |
|---|
| s1 | 4(char) | 4(int) | 4(char) | 12 | | s2 | 4(int) | 2(char) | 2(char) | 8 |
对齐参数上面有提到对齐参数,什么是对齐参数? 对齐参数:n为字节对齐数,其取值为1、2、4、8,(默认值取决于编译器)VC++6.0中n 默认是8个字节 对齐数=编译器默认的一个对齐数与该成员大小的较小值 再看看下面的例子,对比上面对齐参数默认为8时的结果
修改对齐参数可以通过 #pragma pack(n)//设置对齐参数
#pragma pack())//取消设置的默认对齐参数,还原为默认
来指定对齐参数
为上面的例子指定对齐参数: #pragma pack(1)
struct S1{
char a;
int b;
char c;
};
#pragma pack()
#pragma pack(1)
struct S2{
int a;
char b;
char c;
};
#pragma pack()
对齐参数为1
可以看到,分配的空间都变成了6字节,2个char 各占用1字节,int占用4字节 | 结构体 | a占用空间\数据类型 | b用空间\数据类型 | c占用空间\数据类型 | 总占用空间 |
|---|
| s1\s2 | 1(char) | 4(int) | 1(char) | 6 |
对齐参数为2将对齐参数改为2,结果如下: 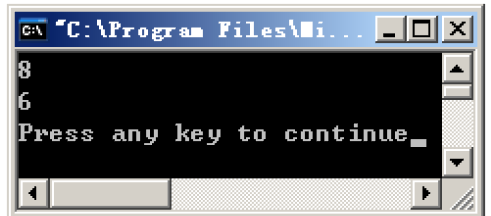
此时空间占用情况如下: | 结构体 | a占用空间\数据类型 | b用空间\数据类型 | c占用空间\数据类型 | 总占用空间 |
|---|
| s1 | 2(char) | 4(int) | 2(char) | 8 | | s2 | 4(int) | 1(char) | 1(char) | 6 |
内存对齐的规则- 数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset(偏移)为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值(或默认值)和)数据成员类型长度中,比较小的那个进行,也就是min{对齐参数,sizeof(数据成员)},在上一个对齐后的地方开始寻找能被当前对齐数值整除的地址
- 结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐.主要体现在,最后一个元素对齐后,后面是否填补空字节,如果填补,填补多少.对齐将按照#pragma pack指定的数值(或默认值)和结构(或联合)最大数据成员类型长度中,比较小的那个进行,也就是min{对齐参数,最大数据成员类型长度}
- 结合1、2推断:当#pragma pack的n值等于或超过所有数据成员类型长度的时候,这个n值的大小将不产生任何效果
用规则分析结果只看规则描述可能还是有些抽象,拿上面对齐参数为2的例子进行分析 先上完整的代码: #include "stdafx.h"
#include <string.h>
#pragma pack(2)
struct S1{
char a;
int b;
char c;
};
#pragma pack()
#pragma pack(2)
struct S2{
int a;
char b;
char c;
};
#pragma pack()
S1 s1;
S2 s2;
int main(int argc, char* argv[])
{
s1.a=1;
s1.b=2;
s1.c=3;
s2.a=4;
s2.b=5;
s2.c=6;
printf("%d\n",sizeof(s1));
printf("%d\n",sizeof(s2));
return 0;
}
这里将s1和s2声明为全局变量,方便查看偏移
分析结果29: s1.a=1;
0040D7C8 mov byte ptr [s1 (00427e48)],1
30: s1.b=2;
0040D7CF mov dword ptr [s1+2 (00427e4a)],2
31: s1.c=3;
0040D7D9 mov byte ptr [s1+6 (00427e4e)],3
32:
33: s2.a=4;
0040D7E0 mov dword ptr [s2 (00427e40)],4
34: s2.b=5;
0040D7EA mov byte ptr [s2+4 (00427e44)],5
35: s2.c=6;
0040D7F1 mov byte ptr [s2+5 (00427e45)],6
通过反汇编得到各个成员所占用的内存空间(之前的数据也是这样得来的) | 结构体 | a占用空间\数据类型 | b用空间\数据类型 | c占用空间\数据类型 | 总占用空间 |
|---|
| s1 | 2(char) | 4(int) | 2(char) | 8 | | s2 | 4(int) | 1(char) | 1(char) | 6 |
数据成员的对齐对于s1: - 首先存储的是char类型的a,分配在00427e48这个地址(这个地址也是对齐参数的整数倍)
- 接下来要在a后面分配的是int类型的b,由于int为4字节,取min{sizeof(b),对齐参数}=min{4,2}=2;于是从上一个地址00427e48+1(a占用了1个字节)向后找能够被2整除的地址来存储b,也就是对应的s1+2 (00427e4a)
- 最后要在b后面分配的是char类型的c,取min{sizeof(c),对齐参数}=min{1,2}=1;于是从上一个地址00427e4a+4(b占用了4个字节)开始向后找能够被1整除的地址来存储c,也就是对应s1+6 (00427e4e)
对于s2: - 首先存储的是int类型的a,分配在00427e40这个地址(这个地址也是对齐参数的整数倍)
- 接下来要在a后面分配的是char类型的b,取min{sizeof(b),对齐参数}=min{1,2}=1;于是从上一个地址00427e40+4(a占用了4个字节)向后找到能够被1整除的地址来存储b,也就是对应的s2+4 (00427e44)
- 最后要b后面分配的是char类型的c,取min{sizeof(c),对齐参数}=min{1,2}=1;于是从上一个地址00427e44+1(b占用了1个字节)向后找到能够被1整除的地址来存储c,也就是对应的s2+5 (00427e45)
结构体整体的对齐无论是对于结构体s1还是结构体s1,对应的min{对齐参数,最大数据成员类型长度}=min{2,4}=2
对于s1: 前面数据成员对齐后的总长度为7,因为:s1+6 (00427e4e)+1(加上c所占用的空间)=s1+7 7并不是2的整数倍,于是要在后面补空字节,补1个空字节,使得总长度为8
对于s2: 前面数据成员对齐后的总长度为6,因为:s2+5 (00427e45)+1(加上c所占用的空间)=s2+6 6正好是2的整数倍,于是无需在后面补空字节,总长度为6 补充无论是将结构体作为参数传递还是作为返回值传递,期间都有大量的内存复制操作,显然实际使用中并适合采用如此耗费性能的操作,一般是使用指针来进行传递的 对于结构体的对齐,不仅仅要考虑结构体成员的对齐,还要考虑结构体整体的对齐 结构体里面使用的static变量在用sizeof进行大小计算时是不会将其算进去的,因为静态变量存放在静态数据区,和结构体的存储位置不同
版权声明:本文由 lyl610abc 原创,欢迎分享本文,转载请保留出处
|
 发表于 2021-03-14 23:14
发表于 2021-03-14 23:14





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助