本帖最后由 sleepyou 于 2022-08-02 22:15 编辑
超级简单爬取笔趣阁小说的Python代码,只需要一个Python环境就能运行技术栈:requests,xpath 直接上代码 import os
import requests
from lxml import etree
def download_txt(name):
params = {
"keyword": name
}
host = "https://www.1biqug.com"
resp = requests.get("https://www.1biqug.com/searchbook.php", params=params)
html = resp.content.decode()
html = etree.HTML(html)
ret_list = html.xpath("//li/span[@class='s2']/a/@href")
detail_url = host + ret_list[0]
resp = requests.get(detail_url)
html = etree.HTML(resp.content.decode())
ret_list = html.xpath("//div[@id='list']//dd//a/@href")
print(ret_list)
if not os.path.exists("./{}".format(name)):
os.mkdir("./{}".format(name))
for ret in ret_list[12:]:
url = host + ret
resp = requests.get(url)
info = resp.content.decode()
html = etree.HTML(info)
title = html.xpath("//h1/text()")
print(title[0])
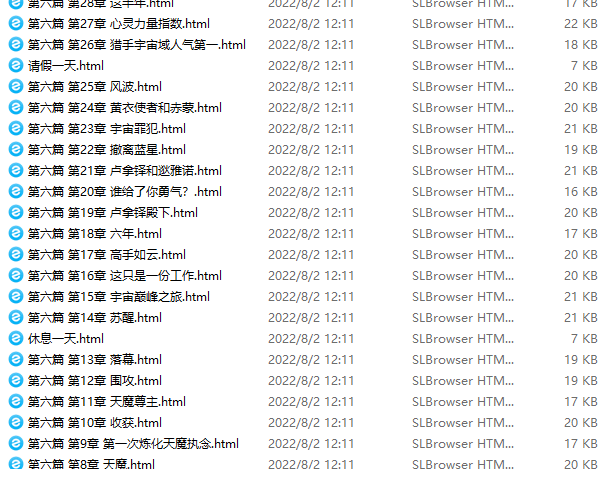
path = os.path.join(name, title[0] + ".html")
path = path.replace("*", "")
with open(path, 'w', encoding="utf8") as f:
f.write(info)
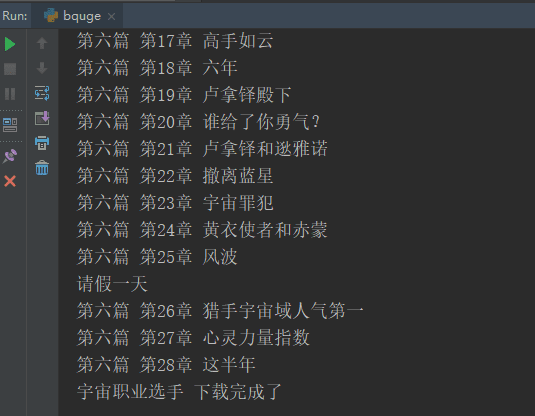
print(name, "下载完成了")
if __name__ == '__main__':
story = input("请输入小说名")
download_txt(story)
|
 发表于 2022-08-02 22:15
发表于 2022-08-02 22:15





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助