本帖最后由 blindcat 于 2023-10-28 23:53 编辑
前言经过我在 必应搜索的搜索与调查,有软件可以下载书链 bookln 上的图书,也有一些文章从 js 逆向写 python 代码批量下载。 诚然,在浏览器中批量下载图片最简单的方式是使用 “图片批量下载插件”、或者油猴插件中现有的 JS 代码,然吾辈修仙者(代码修仙)虽有前人经验传承、功法灵器,但若不加以试炼、斗法,又如何成为一方顶天立地的强者? 虽有人反驳:“能杀敌就行(能达到目的,下载到内容就行)”,但不要忘了,仙道渺渺,大道无情,今有前人炼制的灵器(写好的程序)可以制敌,但未来命运无常,遇凶险绝地而灵器被压制又奈何?? 是以:最重要的还是个人修为,除非不修行了。 所以本文最主要的是 分析 JS 代码的思路、编写 Python 代码生成带书签的 PDF 的思路。网页的分析是在北京时间 10/20/2023 进行,将来网页变动此文也不会去适应网站的变化,不过此文阅读下来想必大家对于今后的斗法有一定的帮助。 另外,本人现在练气一层中期,只好选择这种一阶凶兽作为练法对手了。 战斗准备斗法战场:window 10, 浏览器 Edge。 携带凡器:postman。 法力派别:python 3.10 关于书链中书籍的链接分类经过调查,书链的链接有以下几种分类: - 以
sample.htm 结尾,其处理方式应该和 sample2 一样。 - 以
sample2.htm 结尾,如 https://mp.zhizhuma.com/book/sample2.htm?code=174ef803EE&shelfCode=D5831a7B3。
在网页 [【爬虫项目】书链平台试卷下载 - 大数据男孩 - 学习编程路上的点点滴滴 (bigdataboy.cn)](https://bigdataboy.cn/post-205.html) 处已有人写了分析过程。 - 以
ebook.html 结尾,如 https://mp.bookln.cn/book/ebook.htm?bookId=385519&srcchannel=mp。
此种形式我没有在网上搜到相关的文章,所以正如本文的标题所言,本次分析就是 ebook 结尾的书籍。
网页寻踪!确定数据来源在正式斗法之前需要明确目标: - 将书籍的图片都下载下来
- 将图片生成
PDF - 有书签的话就添加书签咯
好!现在开始,打开网页 https://mp.bookln.cn/book/ebook.htm?bookId=385519&srcchannel=mp。 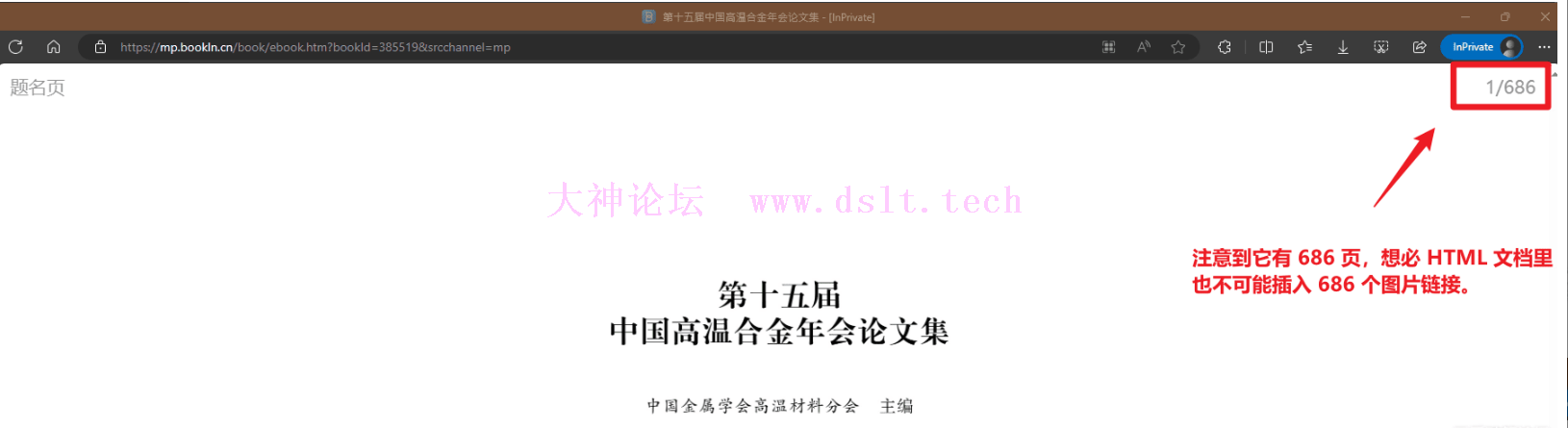
第一步,是要确定它到底收不收费,收费的话咱还是溜了吧…………还好经过测试,它不收费,那继续。 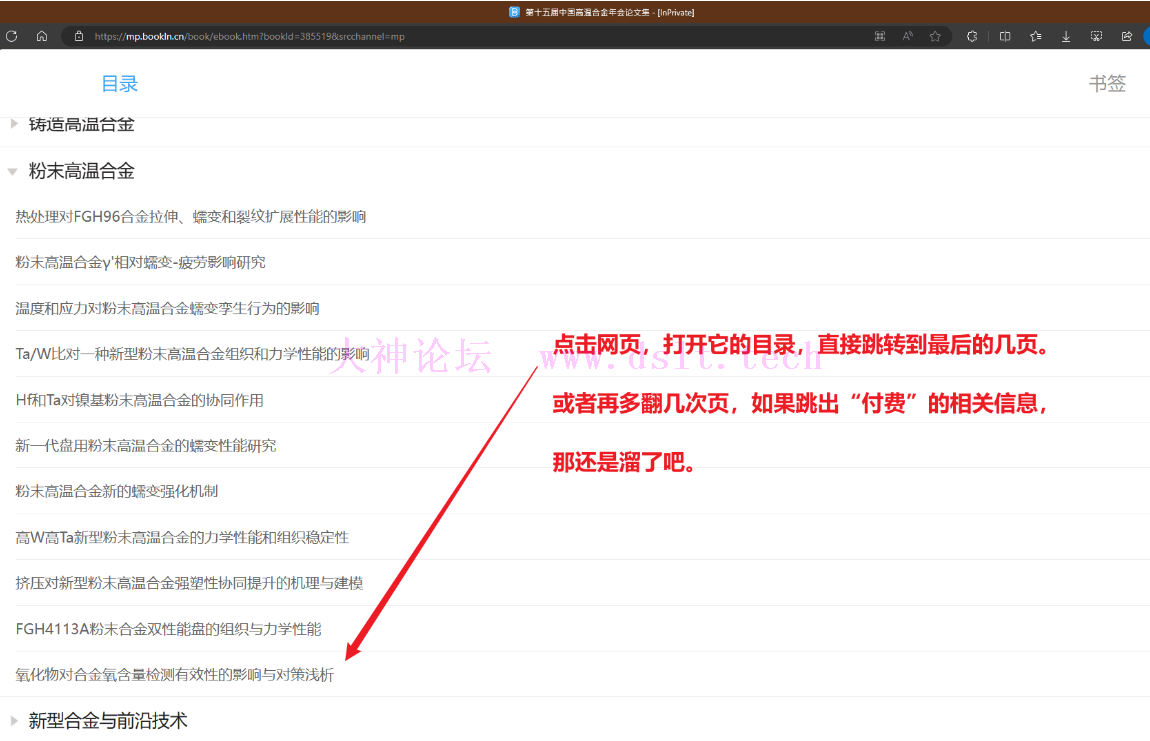
然后在抓包界面先查看图片的请求,知道了它是 .jpg 格式。 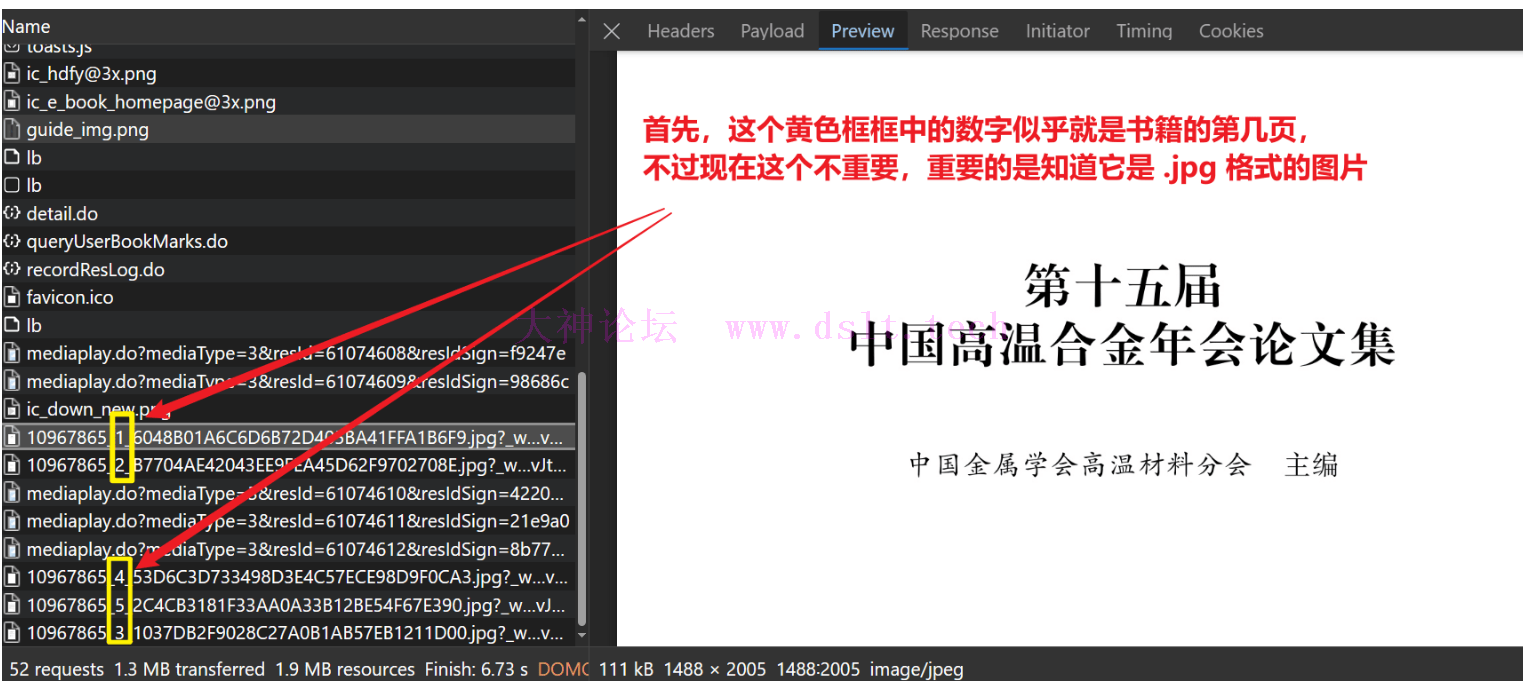
然后在 HTML 中搜索 .jpg、或者看一看有什么可疑的数据,毕竟通常都存在 此地无银三百两 的情况,不过经过实验都没有找到结果,那只好从请求中分析了。 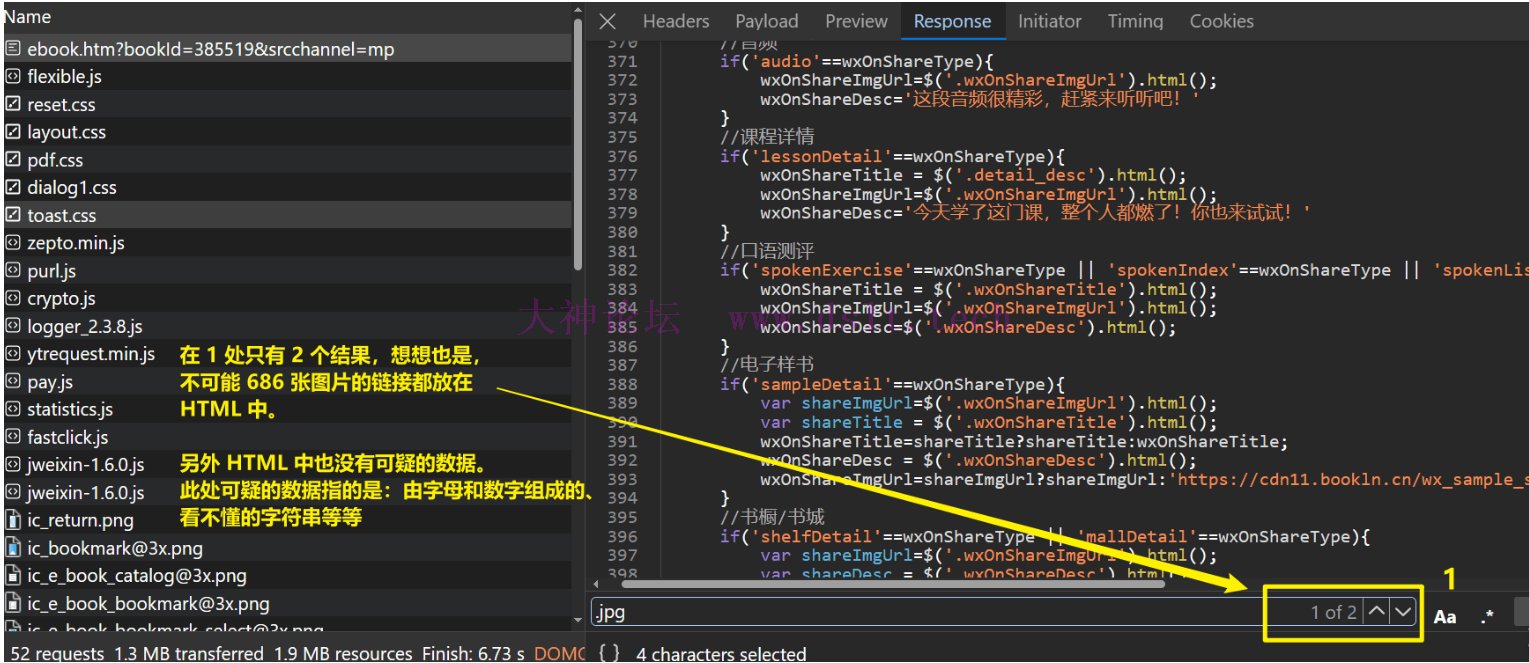
确定关键的请求 detail_do_url首先大致浏览所有请求,发现了一个最可疑的链接,因为它包含了书籍的详细信息——除了图片的链接。 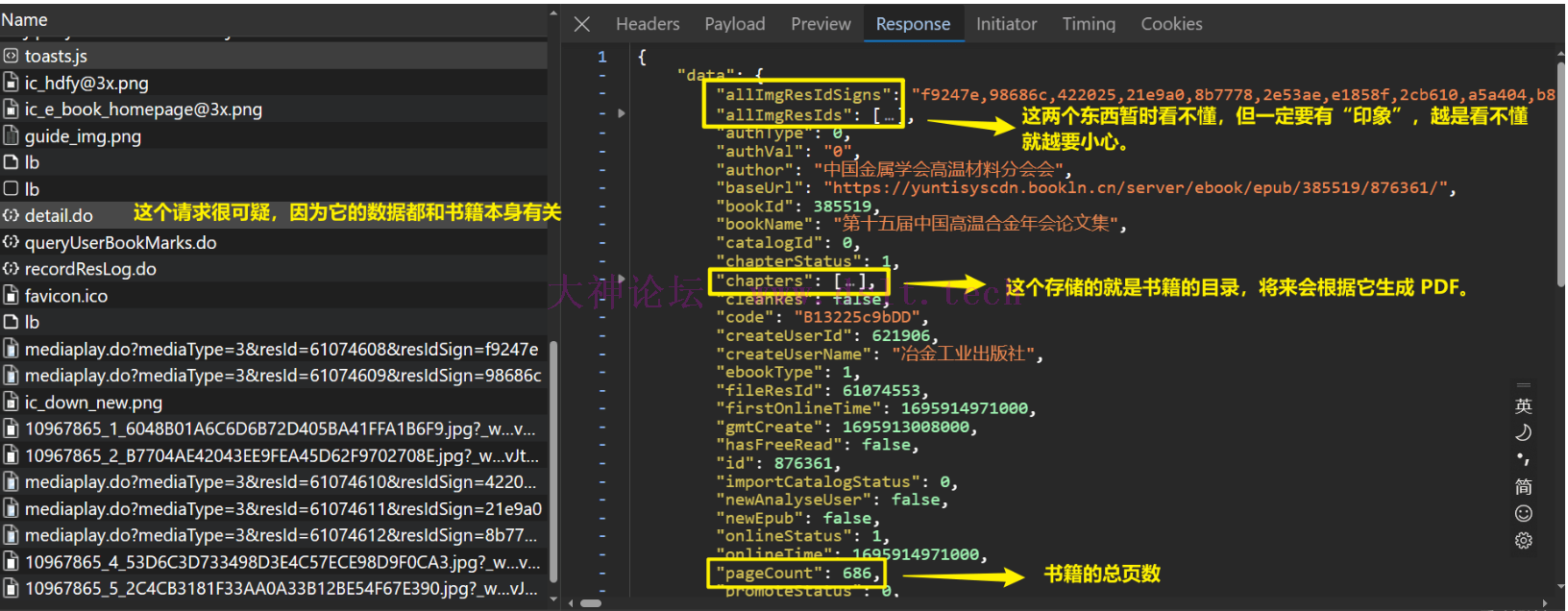
现在为了便于讨论,我将上述请求的链接暂时命名为 detail_do_url,将它返回的 JSON 数据称之为 detail_do_data. 该请求的具体细节暂时不用细究,因为还没有找到书籍的图片下载链接的逻辑。 现在,知道了 detail_do_data 也不清楚图片链接是怎么来的呀,那就只好从图片请求入手了,发现了重点!图片链接是从另一个请求来的! 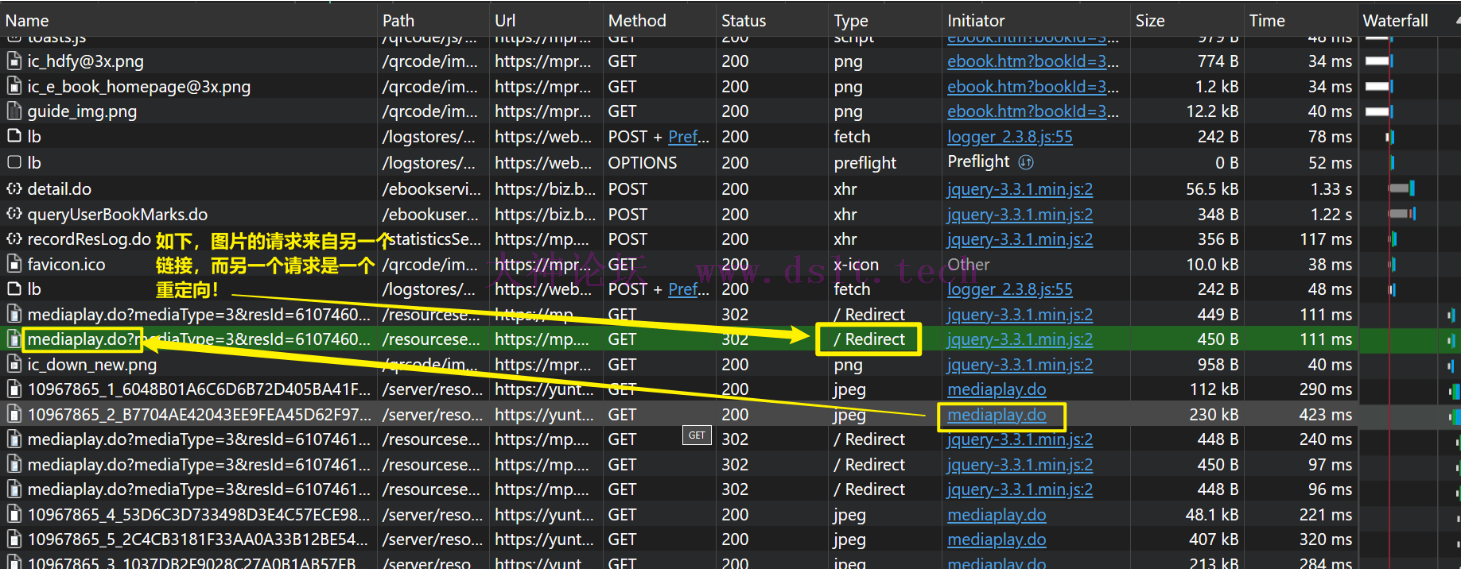
另外,上面那个绿色的行是 Edge 的一个功能:按住键盘的 Shift 键,然后鼠标移动到某个请求中,它能找到该请求来自哪一个请求的内容。我也是最近看 B 站的逆向视频 学到的。 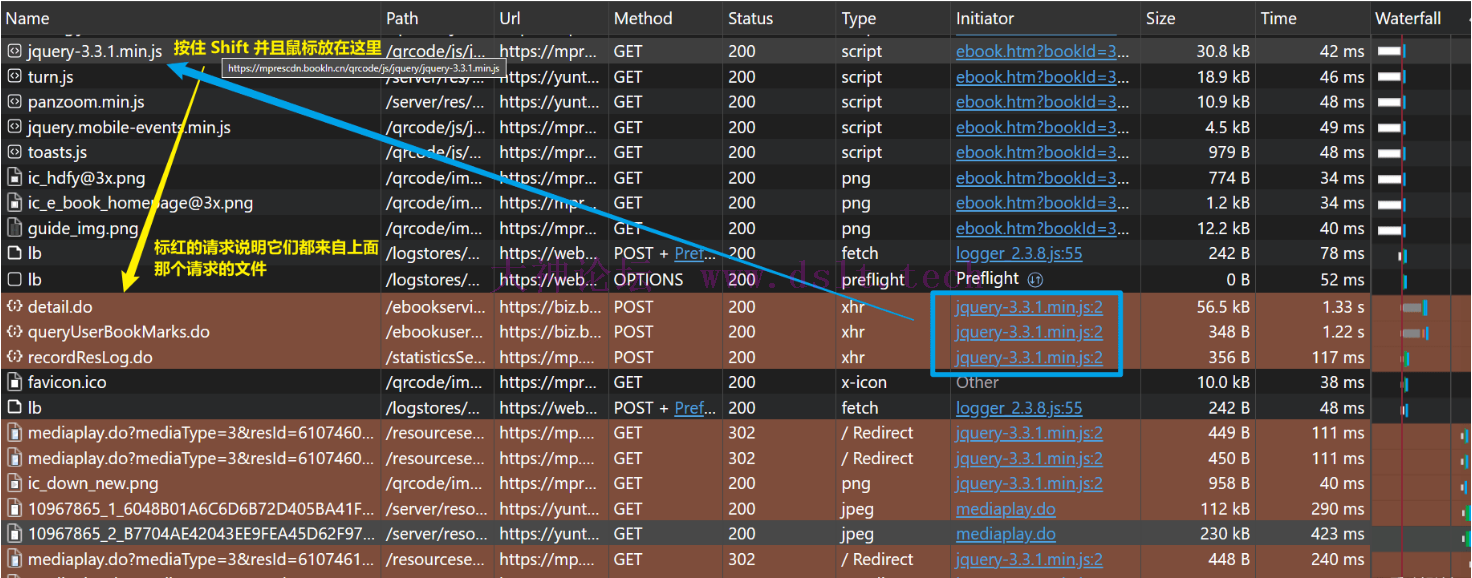
所以现在来到了那个 mediaplay_do_url,注意,这里又暂时起了一个名字哟,查看该请求的信息。 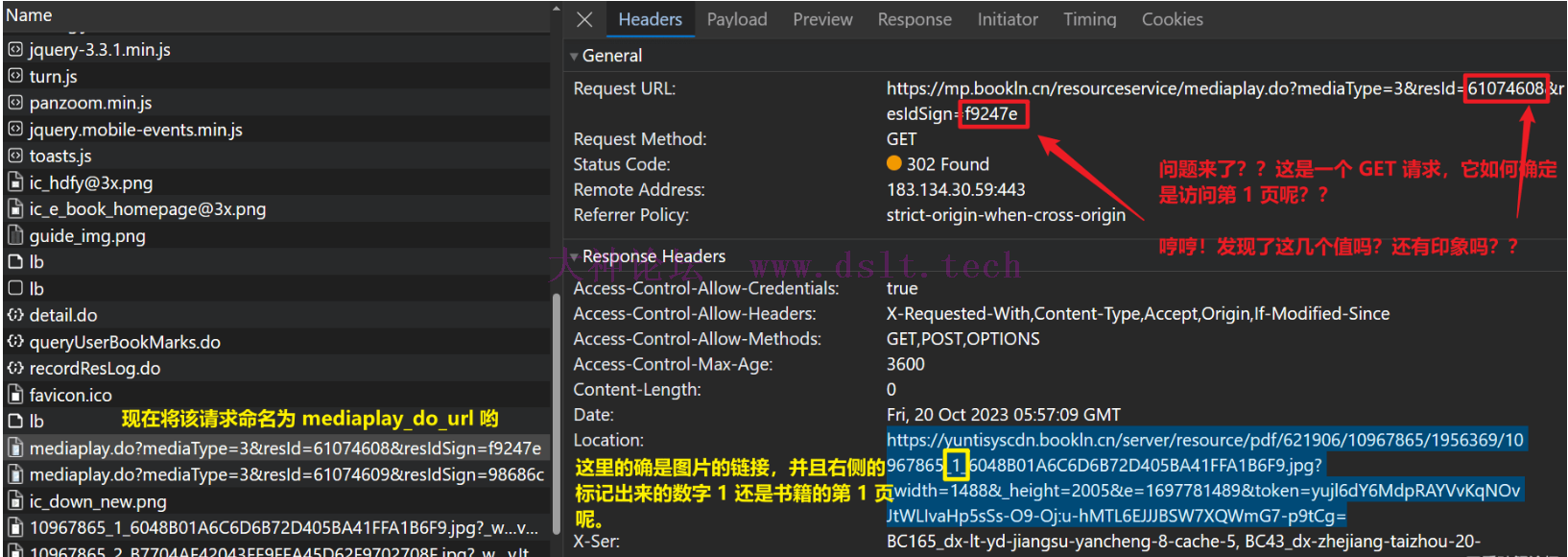
没错!细心的大家想必发现了重点! 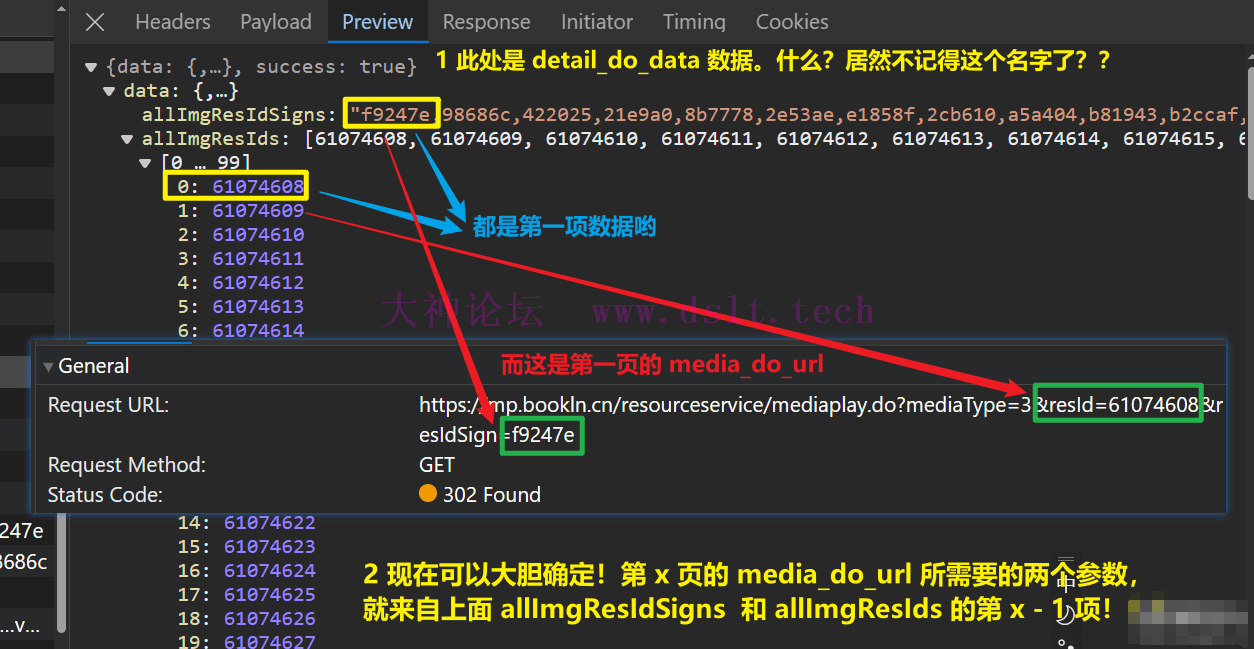
确定流程现在就可以基本确定整个处理过程了,如下图所示(什么??不记得下面各个名词的含义了??) 
法力激荡!力破 detail_do_url根据上文的分析,现在需要获取到 detail_do_data,自然就要分析 detail_do_url 了,下面是它的请求信息,能看得出的先做出判断: # POST 请求
https://biz.bookln.cn/ebookservices/detail.do
# 请求头如下
headers = {
"authority": "biz.bookln.cn",
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "en",
"cache-control": "no-cache",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
# 这个可能需要
"origin": "https://mp.bookln.cn",
"pragma": "no-cache",
# 这个可能需要
"referer": "https://mp.bookln.cn/",
"sec-ch-ua": "^\\^Chromium^^;v=^\\^118^^, ^\\^Microsoft",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "^\\^Windows^^",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46"
}
# POST 的值
data = {
# 书籍的 ID,还记得这本书的链接吗??就在那里
"bookId": "385519",
# 时间戳
"_timestamp": "1697781426",
"_nonce": "ca32554fe7ef41c588b5aa9dcfca1d0d",
"_deviceid": "yda2ce4kwupcksvb89214",
"_traceId": "2023102013570630227139921303821c",
"_sign": "0DD682FCDAABE7685537"
}
其它的只好细细分析了。这里我就全局搜索了,因为这些 POST 的字段名都很有个性,所以很好找,如下。 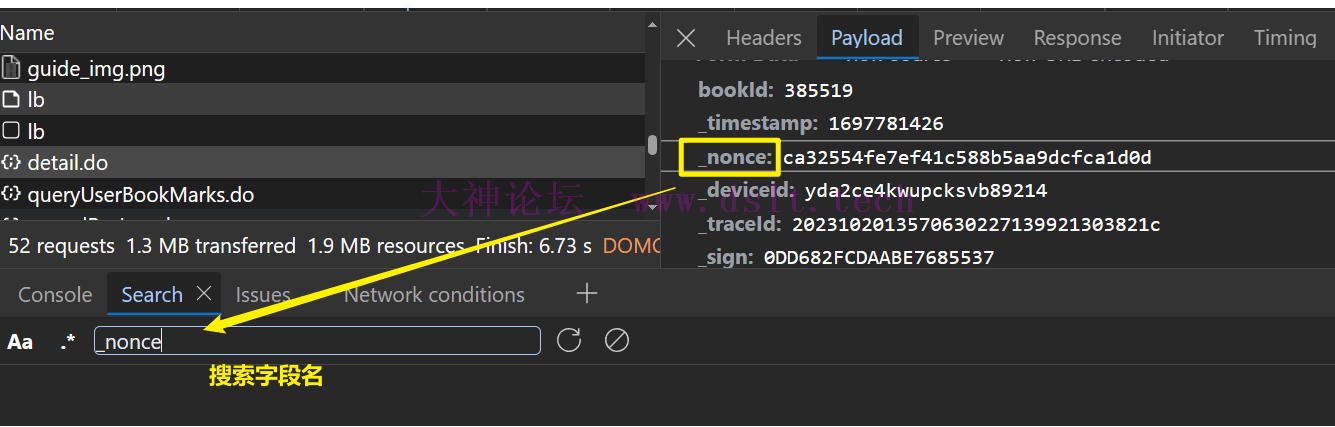
下面开始一一确认 POST detail_do_url 时所需要的数据。 关于 bookId本书籍的链接是 https://mp.bookln.cn/book/ebook.htm?bookId=385519&srcchannel=mp,所以可以轻松获取。 关于 _timestamp是一个时间戳,但要注意它只有 10 位数,可用以下 python 代码模拟: from time import time
_timestamp = str(int(time()))
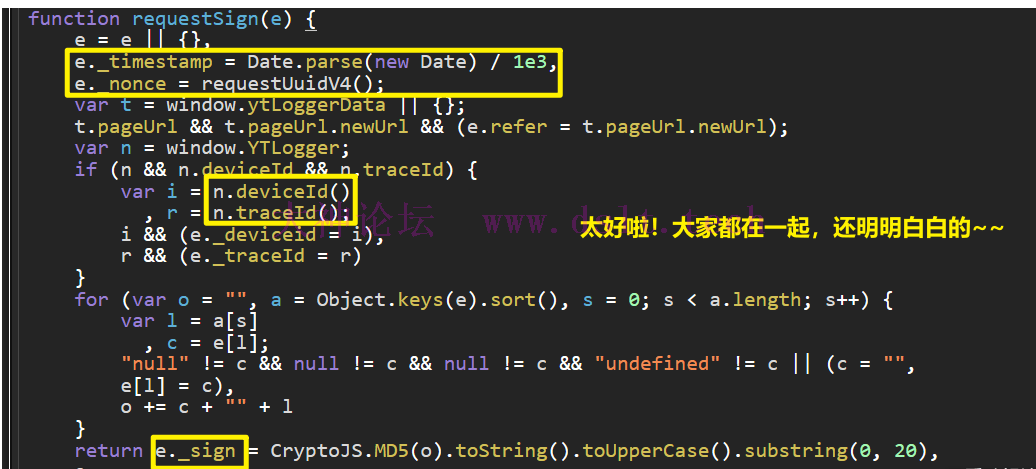
关于 _nonce根据代码 e._nonce = requestUuidV4();,自然要进行调试、跟踪。 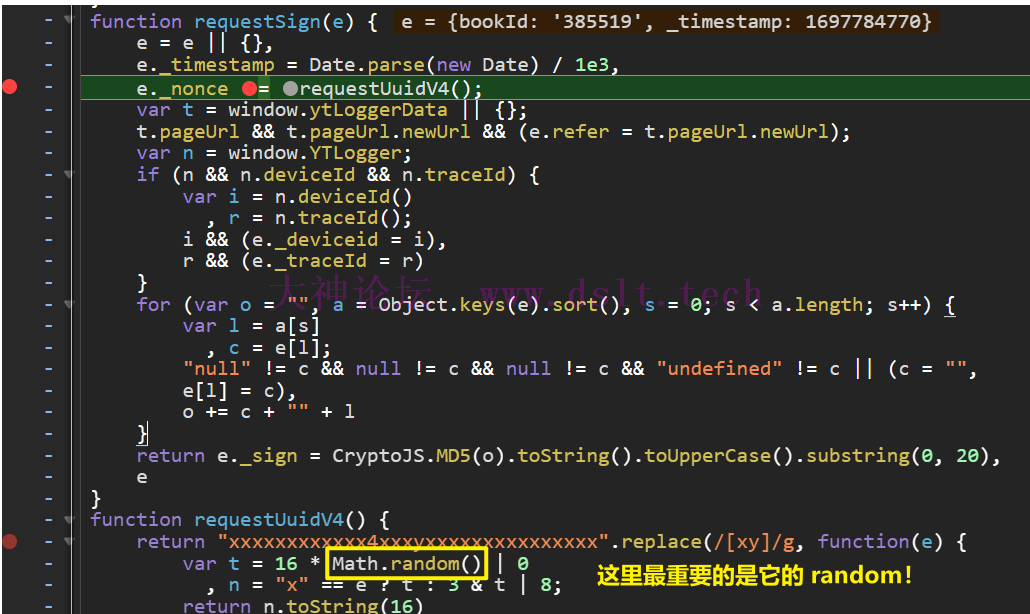
具体代码如下,这里出现了 random,那就说明这个函数的返回值一点也不重要,因为服务端也不会知道 _nonce 具体的值,只能知道它的形式:如它的长度、它的构成等等 function requestUuidV4() {
return "xxxxxxxxxxxx4xxxyxxxxxxxxxxxxxxx".replace(/[xy]/g, function(e) {
// 注意这个 random
var t = 16 * Math.random() | 0
, n = "x" == e ? t : 3 & t | 8;
return n.toString(16)
})
}
所以我们直接随便拿一个已有的 _nonce 值即可,如下 python 代码: _nonce = "ee259673286e4b6da55d4691042e67fc"
关于 _deviceid其具体 js 代码如下: var n = window.YTLogger;
// 这里可以看到 e 的 _deviceid 和 _traceId 都来上面的变量 n
if (n && n.deviceId && n.traceId) {
var i = n.deviceId()
, r = n.traceId();
i && (e._deviceid = i),
r && (e._traceId = r)
}
跟踪进入 window.YTLogger.devicesId(),最终确定它来自 cookie 中的 _ytdeviceid_ 字段哟。 


那么这个 cookie _ytdeviceid_ 是哪里来的??从请求的 cookie 面板中查看其 httpOnly 没有打勾。 恰在此时,想到之前回答某篇帖子时说错了:打了勾说明是服务器设置的,没打勾则只能说明 js 可读写该 cookie 值。 
先清空网站所有数据,再 hook 它。 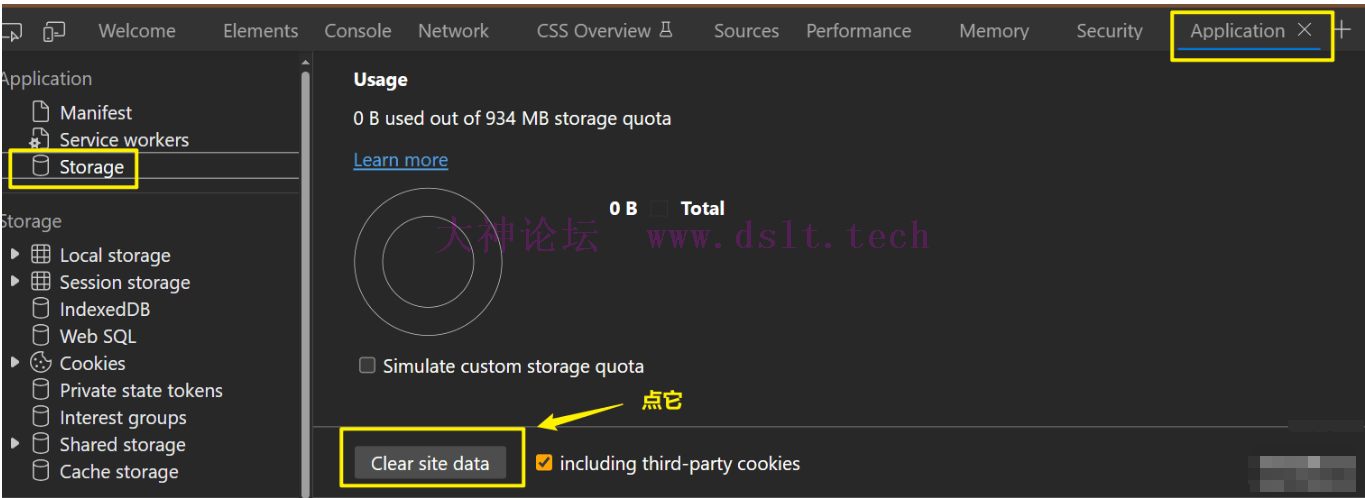
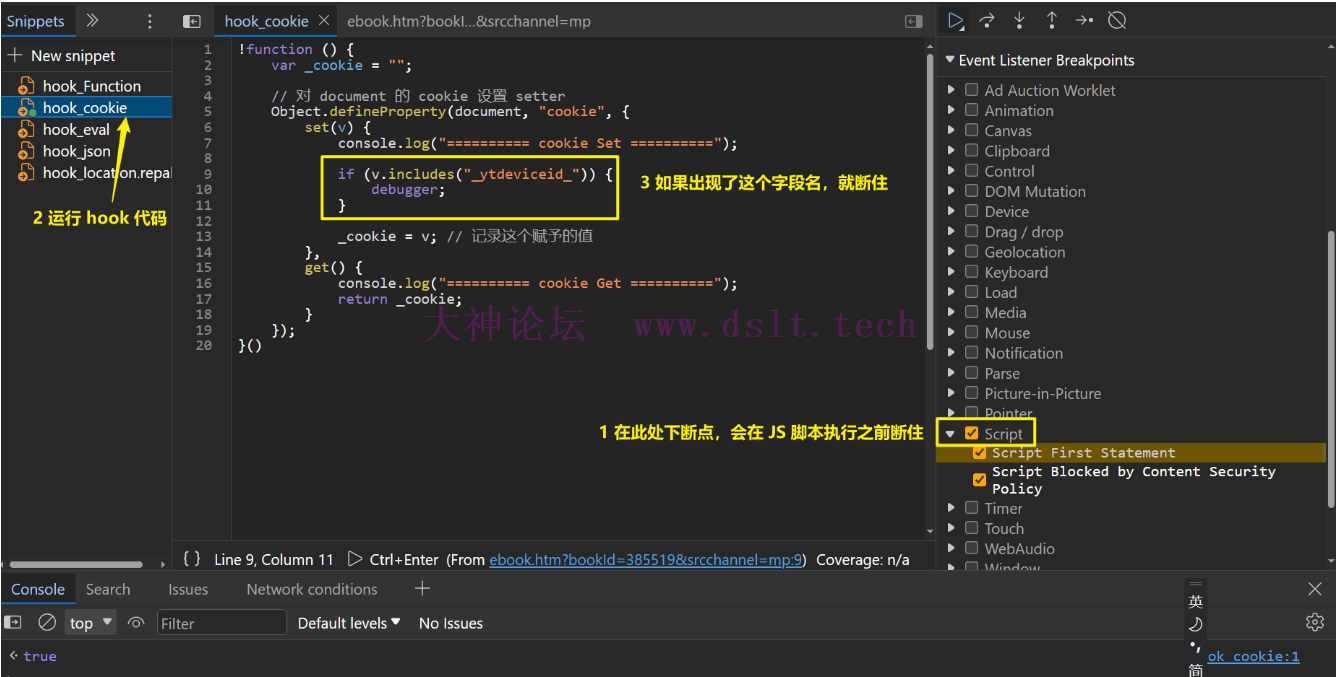
放开上图中的 script 断点,继续执行,看到结果啦!虽然服务器 Set-Cookie 了,但不一定会设置 http only 啦。 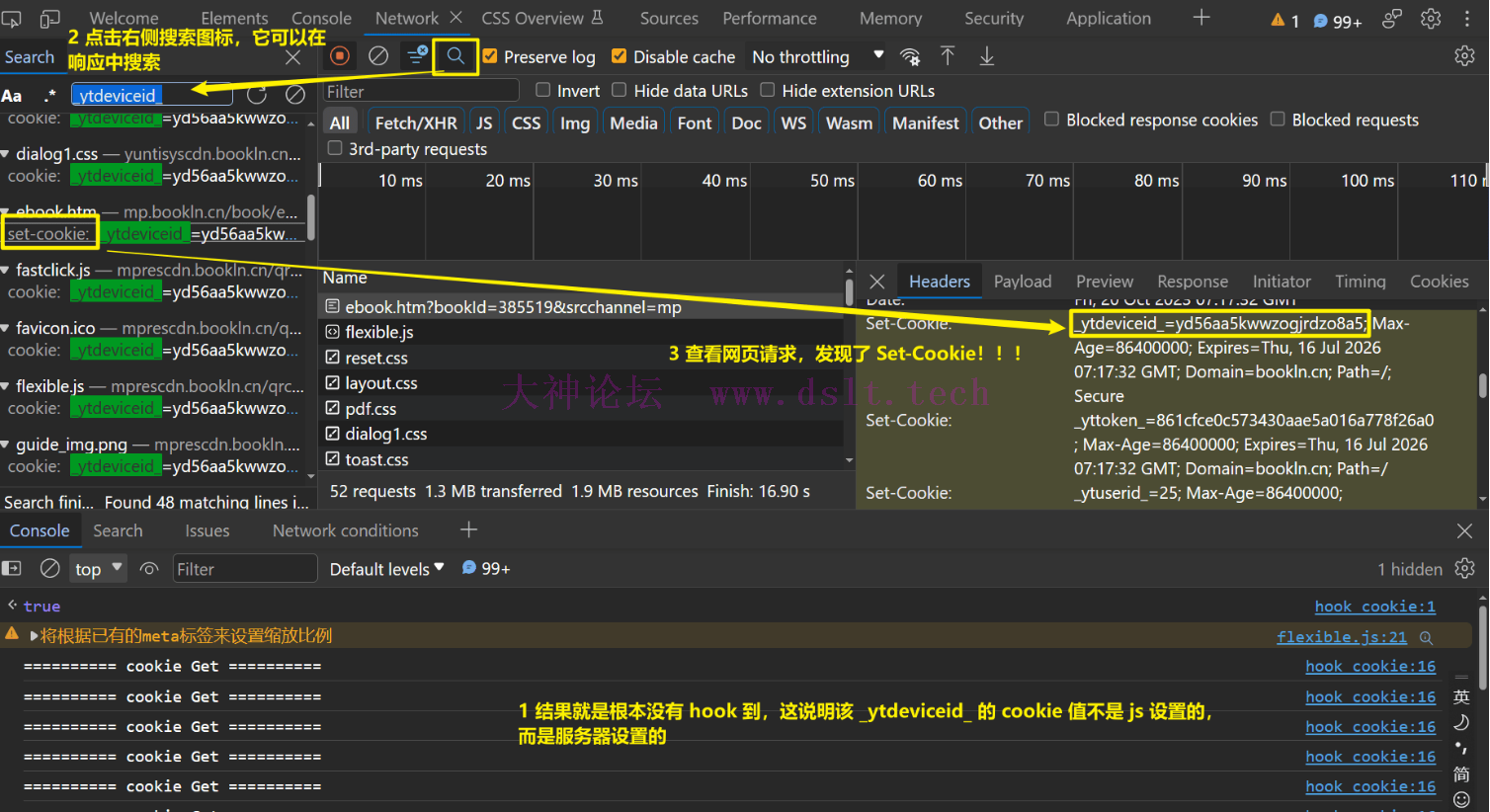
至此,可以写出如下 python 代码。 import requests
# 需要保存 cookie 就用它啦
SESSION = requests.Session()
url = "https://mp.bookln.cn/book/ebook.htm?bookId=385519&srcchannel=mp"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46"
}
# 因为只需要 Set-Cookie 的值,所以甚至都不需要 get,发送一个 head 就行
SESSION.head(url,headers=headers)
_deviceid = SESSION.cookies["_ytdeviceid_"]
print(_deviceid) # yd71cd5piyue5lz10fa0
关于 _traceId它和 _deviceid 一样都来自 window.YTLogger,根据代码跟踪进入 window.YTLogger.traceId();。 


最终确定它来自 sessionStorage! 

现在的问题就是这个 tractId 的值是怎么生成的了,如下确认位置在 genTraceId 函数 ,然后下断点。 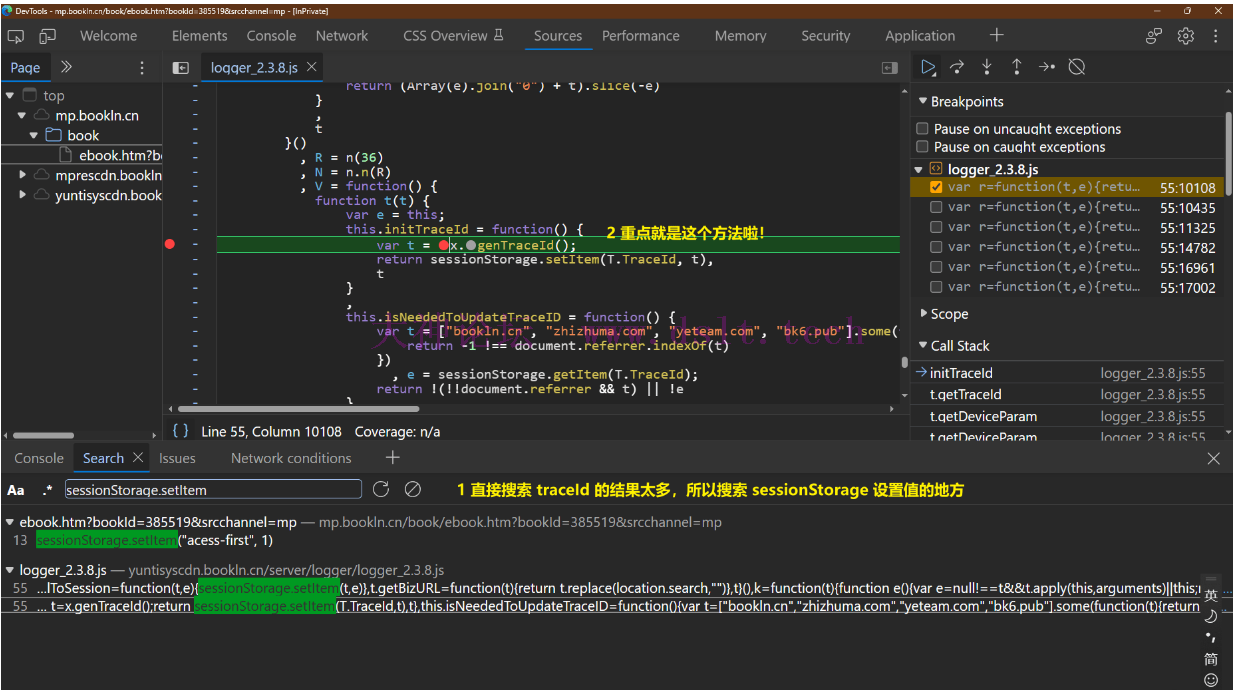
然后需要去清空 sessionStorage。 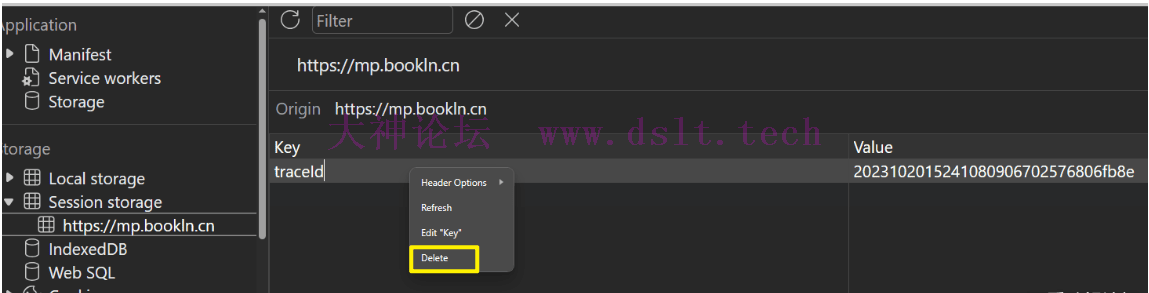
刷新网页!进入断点! 
分析其 JS 代码代码如下: // 取自 https://yuntisyscdn.bookln.cn/server/logger/logger_2.3.8.js
t.genTraceId = function() {
var e = t.current() + t.random() + "";
return e + C()(e).substring(0, 5)
}
关于 t.current// 其中 t.current 代码如下
t.current = function() {
var e = new Date;
return e.getFullYear().toString() + t.prefixInteger(e.getMonth() + 1, 2) + t.prefixInteger(e.getDate(), 2) + t.prefixInteger(e.getHours(), 2) + t.prefixInteger(e.getMinutes(), 2) + t.prefixInteger(e.getSeconds(), 2) + t.prefixInteger(e.getMilliseconds(), 3)
}
发现它就是 “年、月、日、时、分、秒” 各取 2位数,但是最后的毫秒取 3 位数,可用以下 代码模拟: from datetime import datetime
e = datetime.now()
# 注意 e.microsecond 取前面 3 位数
current = f"{e.year}{e.month}{e.day}{e.hour}{e.minute}{e.second}{str(e.microsecond)[:3]}"
print(current) # 2023102015514177
关于 t.randomt.random = function() {
for (var t = "", e = 0; e < 10; e++)
// 注意这里的 random
t += parseInt((10 * Math.random()).toString(), 10).toString();
return t
}
正如之前所说,既然有了 Math.random,所以 t.random() 的值不重要,故直接从控制台输出、拿一个用就行。 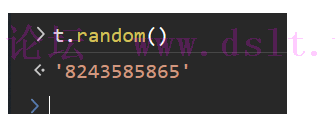
random = "8243585865"
关于 C()(e)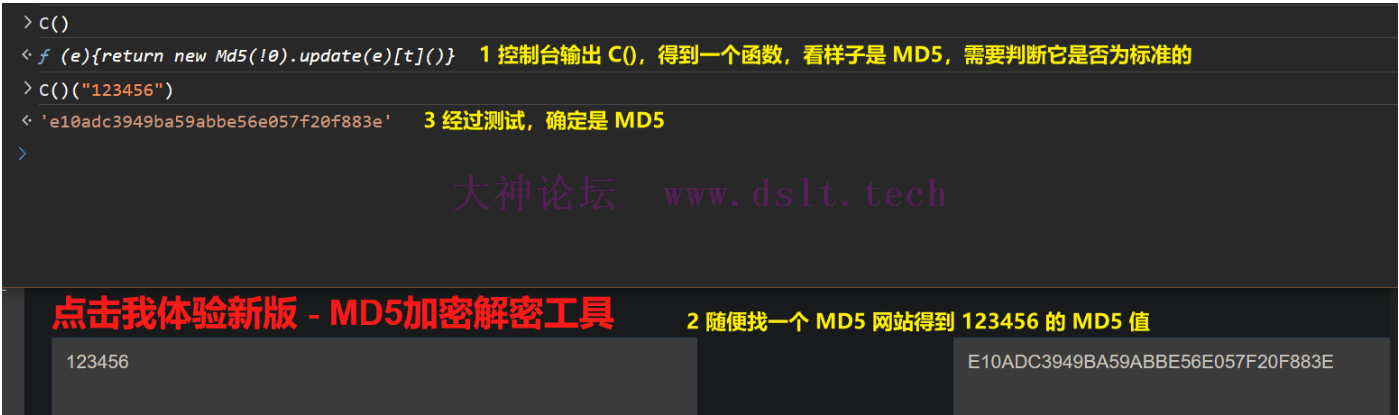
整合代码现在就要将上述代码整合到一个来生成 _traceId。 def get_traceid():
def get_current():
""" 相当于 t.current() """
e = datetime.now()
# 注意 e.microsecond 取前面 3 位数
current = f"{e.year}{e.month}{e.day}{e.hour}{e.minute}{e.second}{str(e.microsecond)[:3]}"
return current
e = get_current() + "8243585865"
# 然后进行 MD5 计算,取末尾的 5 位
return e + hashlib.md5(e.encode()).hexdigest()[:5]
关于 _sign直接分析 js 代码。 // 这里对 e 的字段名进行排序,然后赋值给 a。
for (var o = "", a = Object.keys(e).sort(), s = 0; s < a.length; s++) {
// 取 e 的某个字段名
var l = a\[s\], c = e[l]; // 取该字段对应的值
"null" != c && null != c && null != c && "undefined" != c || (c = "", e[l] = c),
o += c + "" + l // 然后将它们拼接,最终保存到 o 变量
}
// 进行 MD5 啦
e._sign = CryptoJS.MD5(o).toString().toUpperCase().substring(0, 20)
关于上述代码为什么会有 a\[s\] 形式。 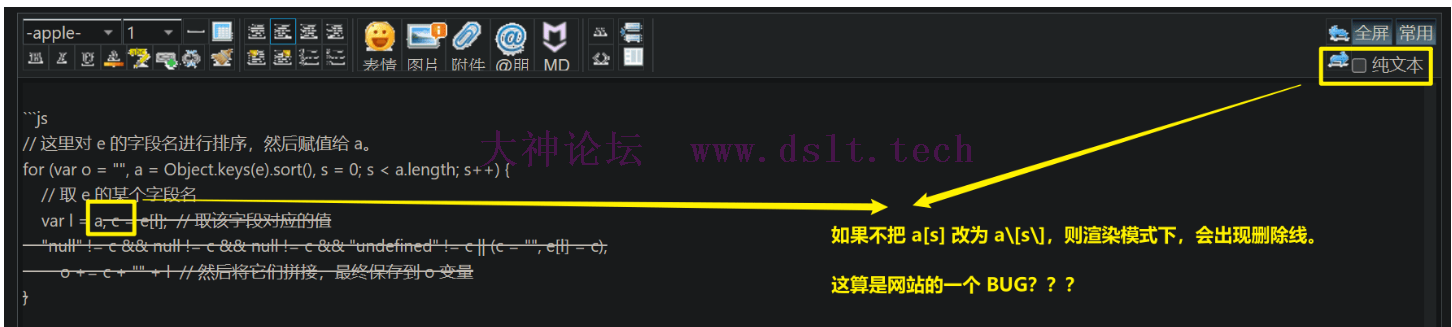
嗯……简单明了,还原成以下代码。 # 这里是调试时取的 e 的值,是为了最后生成结果时可以和网站的结果相互验证
e = {
"bookId": "385519",
"_deviceid": "yd56aa5kwwzogjrdzo8a5",
"_nonce": "b40f2debf66e4fd7a72542b1891ff4e4",
"_timestamp": "1697789171",
"_traceId": "20231020160416548229331105520d30",
}
result = ""
for item in sorted(e.keys()):
result += e[item] + item
print(result)
e["_sign"] = hashlib.md5(result.encode()).hexdigest().upper()[:20]
获取 detail_do_data现在需要将上述代码,整合成函数等供将来使用,如下: import hashlib
from time import time
from datetime import datetime
import requests
SESSION = requests.Session()
NORMAL_HEADERS = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "en",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua": "^\\^Chromium^^;v=^\\^118^^, ^\\^Microsoft",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "^\\^Windows^^",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46",
}
""" 通用请求头 """
BOOK_API_URL = "https://mp.bookln.cn/book/ebook.htm?bookId={}"
""" 访问 ebook 书籍的链接 """
def visit_book_page(book_id: str):
"""访问书籍的首页,获取 Set-Cookie,即获取 _deviceid"""
SESSION.head(BOOK_API_URL.format(book_id), headers=NORMAL_HEADERS)
def _get_post_data_for_detail_do_url(book_id) -> dict:
def get_traceid():
e = datetime.now()
# 注意 e.microsecond 取前面 3 位数
current = f"{e.year}{e.month}{e.day}{e.hour}{e.minute}{e.second}{str(e.microsecond)[:3]}"
e = current + "8243585865"
# 然后进行 MD5 计算,取末尾的 5 位
return e + hashlib.md5(e.encode()).hexdigest()[:5]
def get_sign(e: dict) -> str:
result = ""
for item in sorted(e.keys()):
result += e[item] + item
return hashlib.md5(result.encode()).hexdigest().upper()[:20]
e = {
"bookId": book_id,
"_timestamp": str(int(time())),
"_nonce": "ee259673286e4b6da55d4691042e67fc",
# 先要确保调用了 visit_book_page 方法哟
"_deviceid": SESSION.cookies["_ytdeviceid_"],
"_traceId": get_traceid(),
}
e["_sign"] = get_sign(e)
return e
def get_detail_do_data(book_id: str) -> dict:
"""通过 book_id 访问 detail_do_url 获取 detail_do_data"""
detail_do_url = "https://biz.bookln.cn/ebookservices/detail.do"
headers = {
"authority": "biz.bookln.cn",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"origin": "https://mp.bookln.cn",
"referer": "https://mp.bookln.cn/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46",
}
data = _get_post_data_for_detail_do_url(book_id)
response = SESSION.post(detail_do_url, headers=headers, data=data)
with open("detail_do_data.json", "w", encoding="utf8") as fp:
fp.write(response.text)
return json.loads(response.text)
# 主代码
book_id = "385519"
visit_book_page(book_id)
detail_do_data = get_detail_do_data(book_id)
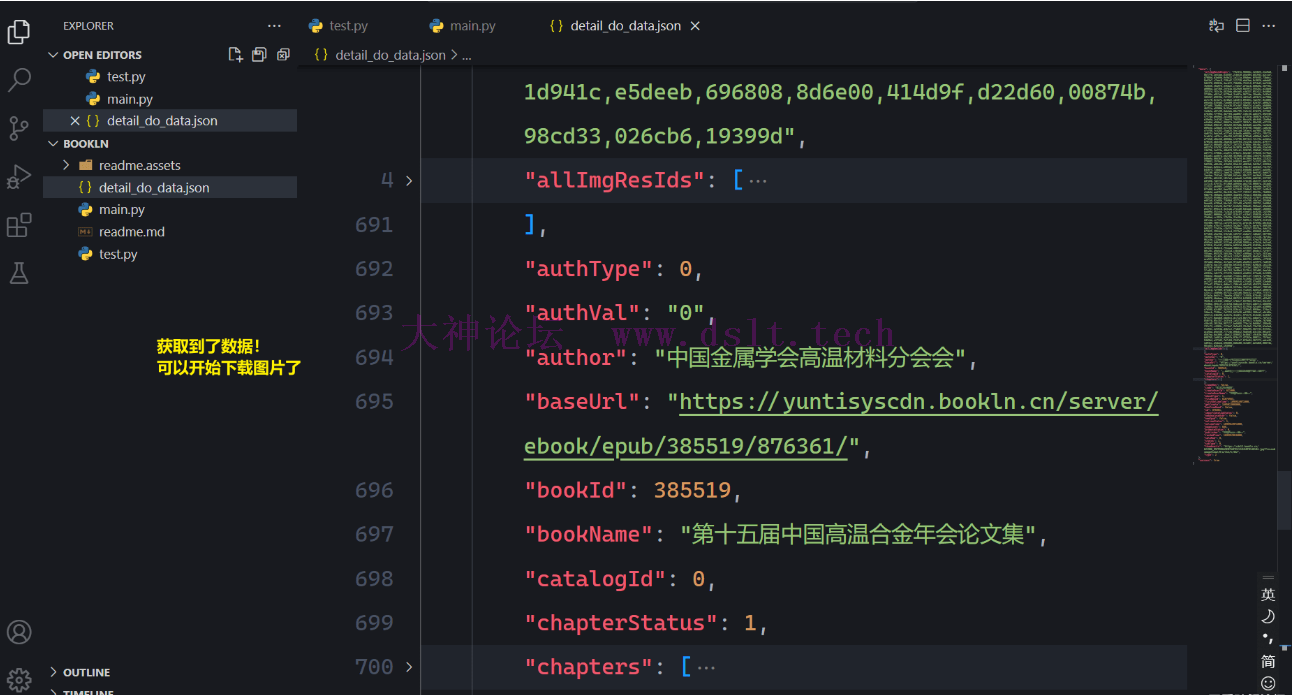
剑势无双!下载图片并生成 PDF上文保存了获取到的 detail_do_data,现在就从该文件读取内容并批量下载图片。 经过测试,访问 mediaplay_do_url 时只需要设置 “支持重定向、设置 Referer” 即可。 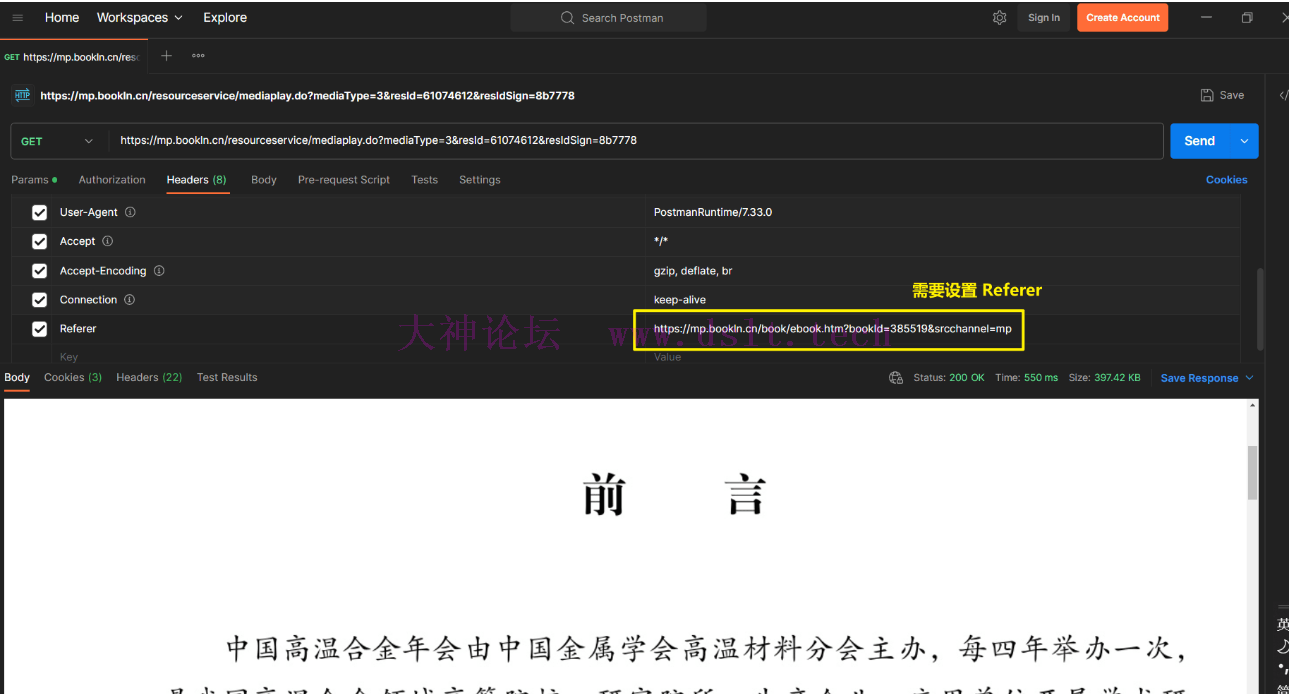
如下,我并没有使用多线程,我的主要目的是分析网站啦。 from pathlib import Path
def download_img(detail_do_data: dict[str, str], directory: Path):
"""下载图片到指定目录"""
# 首先处理用于 media_do_url 请求所需的参数
allImgResIdSigns = detail_do_data["allImgResIdSigns"].split(",")
allImgResIds = detail_do_data["allImgResIds"]
# 它们两个的长度应该相等,并且等于书籍的总页数
assert len(allImgResIds) == len(allImgResIdSigns) == detail_do_data["pageCount"]
# 输出一些书籍信息
print("书籍名:", detail_do_data["bookName"])
print("页数:", detail_do_data["pageCount"])
# 开始准备下载图片
mediaplay_do_url = "https://mp.bookln.cn/resourceservice/mediaplay.do?mediaType=3&resId={}&resIdSign={}"
for i in range(detail_do_data["pageCount"]):
# 生成链接,访问它需要重定向才能下载到图片
url = mediaplay_do_url.format(allImgResIds[i], allImgResIdSigns[i])
# 准备请求头
h = NORMAL_HEADERS.copy()
h.update({
"Referer": BOOK_API_URL.format(detail_do_data["bookId"])
})
# 支持重定向
r = SESSION.get(url, headers=h,allow_redirects=True)
# 保存的文件名
filename = directory / f"{i}.jpg"
with filename.open("wb") as fp:
fp.write(r.content)
print(f"\r下载进度: {i}/ {detail_do_data['pageCount']}", end="", flush=True)
print()
book_id = "385519"
visit_book_page(book_id)
# 从文件读取,因为之前已经获取了 detail_do_data 到本地啦
with open("detail_do_data.json", "r", encoding="utf8") as fp:
detail_do_data = json.load(fp)
# 下载的图片放到脚本所在目录的 download 目录中
d = Path(__file__).parent / "download"
d.mkdir(exist_ok=True)
download_img(detail_do_data["data"], d)
此处没有展示下载的图片,见最后的展示。 好险!压缩图片下载之后看了一下,居然有这么 400 MB 了!可恶!忘了这个了,后文将使用 pillow 库来压缩图片。 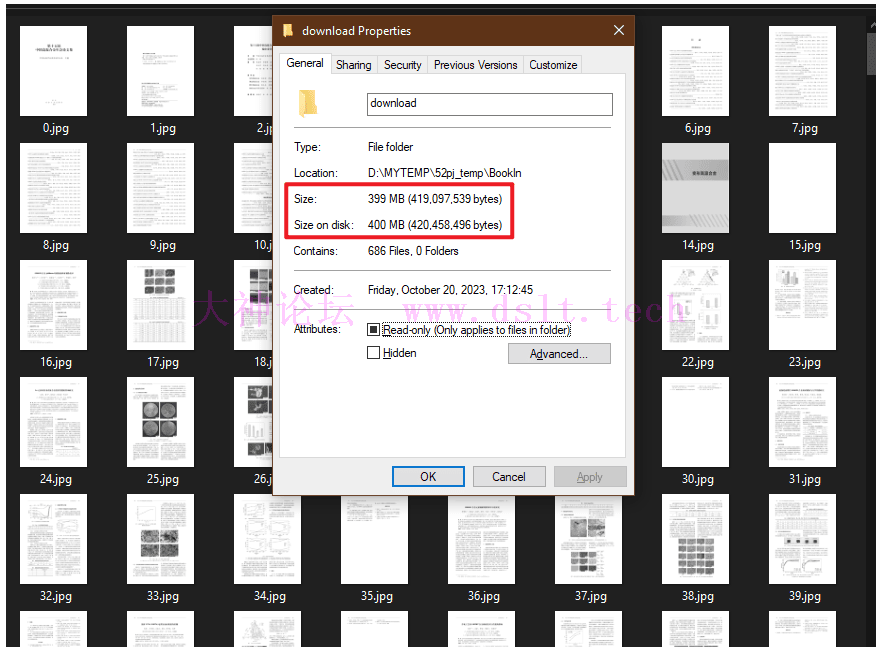
# 简化的代码
r = SESSION.get(url, headers=h,allow_redirects=True)
# 保存的文件名
filename = directory / f"{i}.jpg"
im = Image.open(BytesIO(r.content))
# 进行压缩
im.save(filename, optimize=True, quality=60)
乘胜追击!生成带书签的 PDF这是使用了 python 的 img2pdf 库将图片转成 PDF,然后使用 PyPDF2 库生成带书签的 PDF。 其中书签信息从 detail_do_data["chapter"] 中获取,以下是简单分析: {
"authType": 0,
"authVal": "0",
"bookId": 385519,
"chapterStatus": 1,
"id": 2169992,
"imgResIdSigns": "1a111a,89dbec",
"imgResIds": "61074622,61074623",
# 这是书签的层级,1 就是最顶级
"level": 1,
"name": "变形高温合金",
"orders": 50000000,
# 该书签所在的页面
"pageNo": 15,
# 如果有该属性,则含有子书签
"sections": [
{
"authType": 0,
"authVal": "0",
"bookId": 385519,
"chapterStatus": 1,
"id": 2169993,
"imgResIdSigns": "0f6445,73bdcc,8a43a7,c7aac8",
"imgResIds": "61074624,61074625,61074626,61074627",
# 子书签的层级加 1 了哟
"level": 2,
"name": "GH4151合金Φ300mm均质细晶棒材制备技术",
"orders": 10000000,
# 对应的页面
"pageNo": 17,
"pid": 2169992
},
]
所以有以下代码。 def create_pdf(chapters:dict, directory:Path, PDFFilename: str):
"""
从 chapter 中获取书签信息,
然后将 directory 书签下的所有图片生成 PDF,其名为 PDFFilename
"""
# 先获取所有 img,然后利用 img2pdf 生成一个 PDF
# 确保 directory 书签下只有 .jpg,这里没有做判断哟
imgs = list(directory.iterdir())
# 还需要对它进行排序,因为文件名是 1.jpg 之类的
# 默认情况下,1.jpg 后面反而是 10.jpg 了
# f.stem 获取它的数值部分
imgs.sort(key=lambda f:int(f.stem))
# 然后转为文件名字符串
imgs = [str(item) for item in imgs]
# 将所有文件转为 PDF
raw_pdf = img2pdf.convert(imgs)
# 以下就是 PyPDF2 的用法了
reader = PyPDF2.PdfReader(BytesIO(raw_pdf))
writer = PyPDF2.PdfWriter()
writer.append_pages_from_reader(reader)
# 然后开始处理书签!
# 因为处理书签用的 API add_outline_item 需要知道它的上一层级
def add_outline_item(current_chapters, parent_outline):
""" current_chapters 是特定层级下的所有书签的序列, parent_outline 则是它的上一层"""
for current_chapter in current_chapters:
title = current_chapter["name"] # 书签名
page_no = current_chapter["pageNo"] - 1 # 书签所在的页数,从 0 开始,所以要减少 1
current_outline = writer.add_outline_item(title, page_no, parent_outline)
# 处理子书签
if "sections" in current_chapter:
add_outline_item(current_chapter["sections"], current_outline)
pass
# 开始遍历、添加书签,初始情况下顶层书签是 None 咯
add_outline_item(chapters, None)
# writer.close() # 保存 PDF!!!
writer.write(PDFFilename)
尾声如下对全部代码进行了测试。 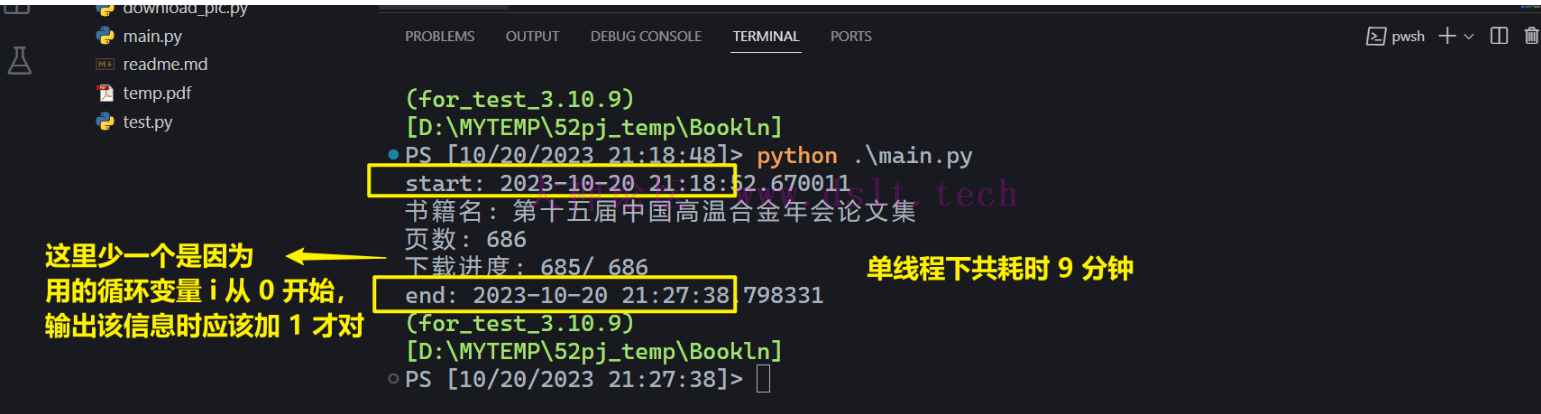
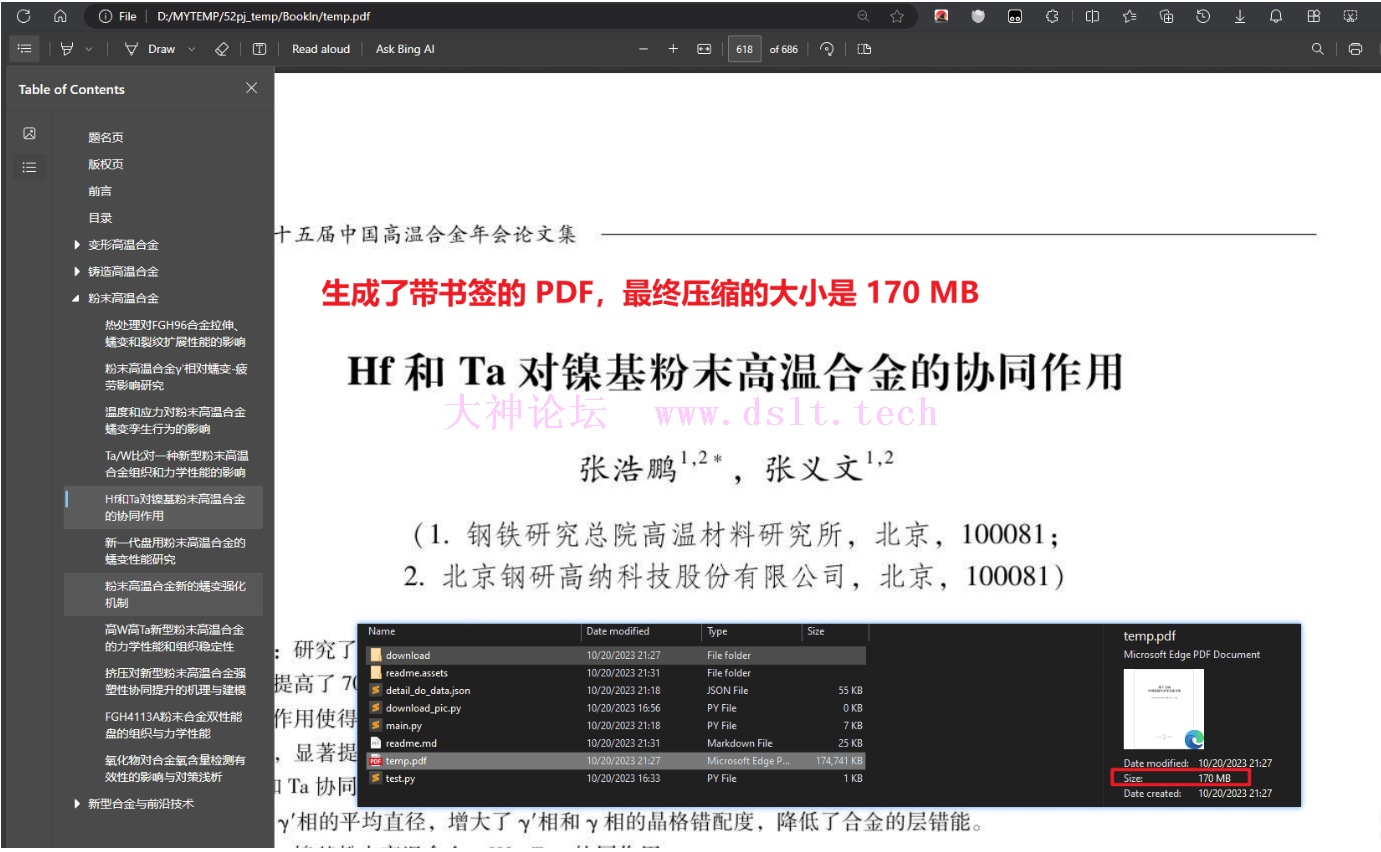
再次说明,我只简单整合了代码,并没有去优化哟,毕竟我的目的是分析网页啦。 另外要着重强调:我只测试了这一个书链的 ebook 链接,因为我不知道这个链接哪来的,所以没有其它的书籍链接来测试。 如果上述思路对某些 ebook 链接并没有用,这……概不负责哈。 留言此次斗法之后将会闭关修炼,争取突破到练气二层。现在层次太低,不适合大量斗法,还是要夯实基础,脚踏实地修炼,精进法力、熟悉武技。 毕竟我没有逆天小瓶、也没有高人传法一夜突破到筑基的奇遇、更不是开局被未婚妻退婚的天选之子。
注:若转载请注明大神论坛来源(本贴地址)与作者信息。
下方隐藏内容为本帖所有文件或源码下载链接:
游客你好,如果您要查看本帖隐藏链接需要登录才能查看,
请先登录
|


 发表于 2023-10-28 23:53
发表于 2023-10-28 23:53





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助