本帖最后由 a1100330 于 2023-12-17 11:22 编辑
有一个需求就是有几十上百个发票需要把关键信息:发票号、发票日期、发票金额、名称等信息提取出来,汇总到excel里面。我的需求很简单,就是把pdf里面的发票或指定尺寸的发票图片信息提取出来,自动保存到本地。
整体的思路是,通过代码把pdf文件转为标准格式的图片(convert_pdf_to_image方法),然后通过定位关键信息的位置,然后通过ddddocr进行识别,目前准确率有待提升。代码如下: from PIL import Image as PI
import io
import os
import ddddocr
import pandas as pd
import easyocr
import cv2
import fitz # PyMuPDF
from PIL import Image
ocr = ddddocr.DdddOcr()
#把pdf转为图片
def convert_pdf_to_image(pdf_path, output_image_path):
# 打开PDF文件
pdf_document = fitz.open(pdf_path)
# 获取第一页
first_page = pdf_document[0]
# 设置DPI(每英寸点数)
dpi = 100.0
# 获取图像
image = first_page.get_pixmap(matrix=fitz.Matrix(dpi / 72, dpi / 72))
# 转换为PIL图像
pil_image = Image.frombytes("RGB", [image.width, image.height], image.samples)
# 调整图像大小
#resized_image = pil_image.resize((image_width, image_height), Image.Resampling.LANCZOS)
# 保存图像
pil_image.save(output_image_path, "PNG")
# 关闭PDF文件
pdf_document.close()
# 读取发票
def readPic(img_url):
#img_url = "pic/fp01.jpg"
with open(img_url, 'rb') as f:
a = f.read()
new_img = PI.open(io.BytesIO(a))
#new_img.show()
return new_img;
#递归遍历文件夹
def traverse_directory(path,file_names):
for root, dirs, files in os.walk(path):
for filename in files:
full_path = os.path.join(root, filename)
if full_path.endswith('.png') or full_path.endswith('.jpeg') or full_path.endswith('.jpg'):
file_names.append(full_path)
return file_names
# 提取发票号码
def parse_invoice(new_img):
# 748 *500 门诊收费票据
# 827 * 552 增值类电子普通发票
# result = reader.readtext(new_img)
# print(result)
w = new_img.width # 图片的宽
h = new_img.height
print('识别图片宽、高为:',w,h)
new_img = new_img.resize((827, int(new_img.size[1] * 827 / new_img.size[0])))
w = new_img.width # 图片的宽
h = new_img.height
print('调整后识别图片宽、高为:', w, h)
tuple_voice_type = (236, 28, 583, 57)
image_voice_type = new_img.crop(tuple_voice_type)
#image_voice_type.show()
voice_type = ocr.classification(image_voice_type)
print('识别出的voice_type为:' + voice_type)
if '医疗' in voice_type:
type = 'menzhen'
elif '普通' in voice_type:
type = 'putong'
else:
type = 'yiliao'
invoice = {}
invoice_type_map = {
#广东增值税电子普通发票
'putong':{
'tuple_voice_no':(642,47,703,65),
'tuple_voice_owner': (137, 122,187,137),
'tuple_voice_date': (641,70,739,88), # let [top] right [bottom]
'tuple_voice_amount': (659, 384, 738,404),
'tuple_voice_amount_cn': (225, 382, 390,405)
},
# 广东省医疗门诊收费票据
'menzhen': {
'tuple_voice_no': (584, 88, 650, 102),
'tuple_voice_owner': (92, 120,133,135),
'tuple_voice_date': (584,121,650,133), # let [top] right [bottom]
'tuple_voice_amount': (495, 335, 559,351),
'tuple_voice_amount_cn': (145, 335, 299,351)
}
}
print(invoice_type_map)
image_voice_no = new_img.crop(invoice_type_map[type]['tuple_voice_no'])
#image_voice_no.show()
voice_no = ocr.classification(image_voice_no)
print('识别出的voice_no为:' + voice_no)
image_voice_owner = new_img.crop(invoice_type_map[type]['tuple_voice_owner'])
#image_voice_owner.show()
voice_owner = ocr.classification(image_voice_owner)
print('识别出的voice_owner为:' + voice_owner)
image_voice_date = new_img.crop(invoice_type_map[type]['tuple_voice_date'])
#image_voice_date.show()
voice_date = ocr.classification(image_voice_date)
print('识别出的voice_date为:' + voice_date)
image_voice_amount = new_img.crop(invoice_type_map[type]['tuple_voice_amount'])
#image_voice_amount.show()
voice_amount = ocr.classification(image_voice_amount)
print('识别出的voice_amount小写为:' + voice_amount)
image_voice_amount_cn = new_img.crop(invoice_type_map[type]['tuple_voice_amount_cn'])
#image_voice_amount_cn.show()
voice_amount_cn = ocr.classification(image_voice_amount_cn)
print('识别出的voice_amount_cn大写为:' + voice_amount_cn)
print('--------------------------------------------------')
invoice['voice_no'] = voice_no
invoice['voice_owner'] = voice_owner
invoice['voice_date'] = voice_date
invoice['voice_amount'] = voice_amount
invoice['voice_no'] = voice_no
invoice['voice_amount_cn'] = voice_amount_cn
#print(invoice)
return invoice
def get_output_list():
pass
#保存excel
def saveExcel(output_list):
writer = pd.ExcelWriter('发票记录.xlsx')
data = pd.DataFrame(output_list)
data.to_excel(writer, 'sheet_1', float_format='%f', header=True, index=False)
writer.close()
if __name__ == '__main__':
pdf_path = r"xxx\pdf"
pic_path = r"xxx\png"
file_names = []
files = traverse_directory(pic_path,file_names=file_names)
print(files)
output_list = []
for img_url in files:
new_img = readPic(img_url=img_url)
invoice = parse_invoice(new_img);
invoice['img_url'] = img_url
output_list.append(invoice)
saveExcel(output_list)
整体的识别效果只能说能够看得懂,后面会优化为一个发票识别小助手,先埋个坑 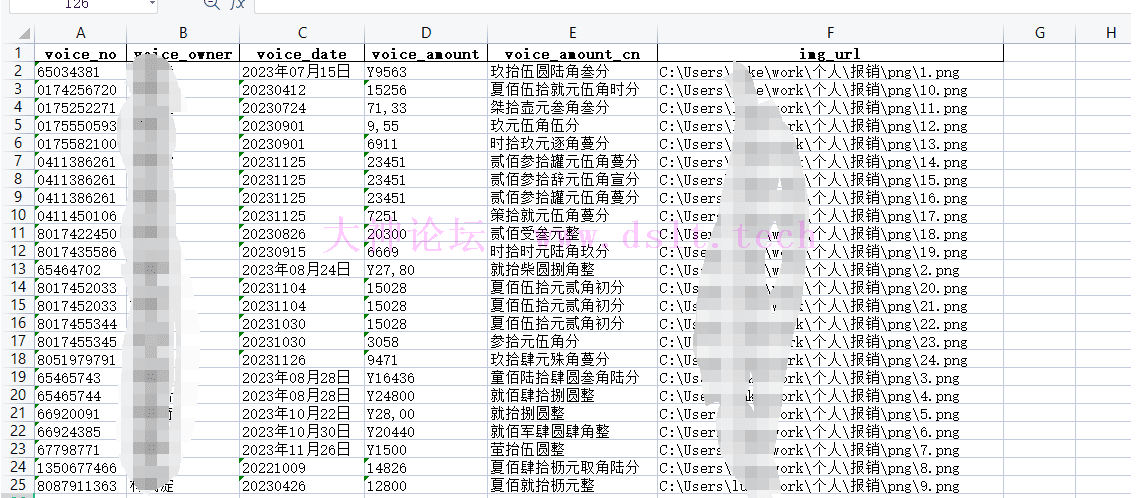
注:若转载请注明大神论坛来源(本贴地址)与作者信息。
|
 发表于 2023-12-17 11:22
发表于 2023-12-17 11:22
 发表于 2023-12-19 11:29:53.0
发表于 2023-12-19 11:29:53.0





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助