本帖最后由 heisezhitong 于 2024-01-30 21:55 编辑
[验证码识别]易盾空间推理验证码识别详细流程本文章所有内容仅供学习和研究使用,不提供具体模型和源码。若有侵权,请联系我立即删除
前言最近遇到了易盾空间推理验证码,在网上找却没有发现很好的教程,便自己研究了一下。
本文使用Python+pytorch+onnx识别验证码,其他语言参考思路即可。 目录准备工作模型训练- yolov5识别目标位置和方向
- AlexNet做颜色分类
图片识别提示词推理
准备工作验证码逆向关于易盾的逆向网上已经有很多教程了,此处我就不过多赘述了。 接下来就是写脚本来获取一些验证码图片和提示词,数量大概在800张到1k左右,图片全部存放到一个文件夹,建议将图片的命名为图片MD5值,这样可以减少命名冲突和相同图片问题,提示词以每行为分隔符存入一个文件内。
1 
2 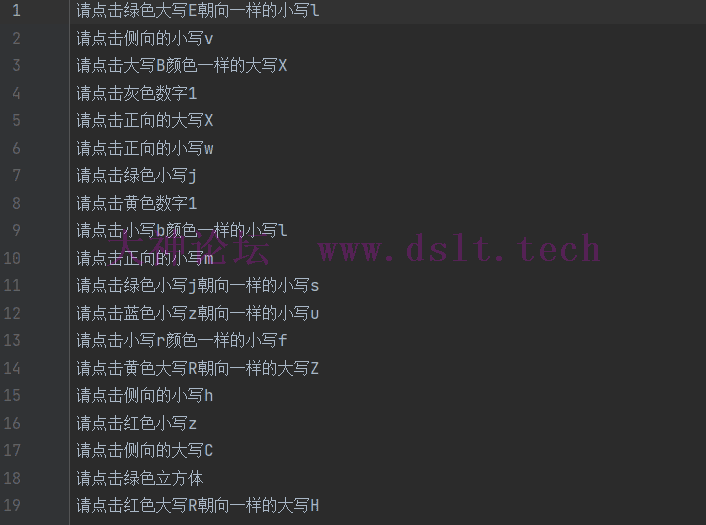
提示词分析我们对提示词文件做词频统计(Word Count),并且每个提示词使用jieba分词来拆分。 import jieba
def split_prompt():
# jieba分词
prompt_path = "prompt.txt"
prompt_list = []
with open(prompt_path, "r", encoding="utf-8") as f:
for line in f.readlines():
prompt_list.append(line.strip().replace("请点击", ""))
# 分词,每一行,统计词频
word_dict = {}
for line in prompt_list:
words = jieba.cut(line)
for word in words:
if word in word_dict.keys():
word_dict[word] += 1
else:
word_dict[word] = 1
# 排序
# word_dict = sorted(word_dict.items(), key=lambda x: x[1], reverse=True)
# 删除无用词
delete_list = ["的", "大写", "小写", "一样", "朝向", "数字", "颜色"]
for word in delete_list:
del word_dict[word]
# 排序
word_dict = sorted(word_dict.items(), key=lambda x: x[0], reverse=False)
print(word_dict)
if __name__ == '__main__':
split_prompt()
去除无用词后结果如下
3 
由此可知,验证码图片中的所有类别 - 物体: 66种
- 大写字母: 26种
- 小写字母: 26种
- 数字(0-9): 10种
- 三维物体: 4种(立方体、圆锥、圆柱、球)
- 方向: 2种
- 颜色: 5种
全部一共有66×2×6=660种,这么多在后面给图片打标时会很麻烦,而且由于种类过多,需要更多的数据集。
所以,我们只需要物体和方向2种即可,那么就一共有66×2=132种(其中圆柱、圆锥、球是没有方向的,为了方便计算我还是算了进去) 数据处理我们使用代码来生成所有的类型: def combine_prompt():
# 大写字母
upper = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
# 小写字母
lower = "abcdefghijklmnopqrstuvwxyz"
# 数字
number = "0123456789"
# 三维物体
three = ["圆柱", "圆锥", "球", "立方体"]
# 颜色
color = ["红色", "绿色", "黄色", "蓝色", "灰色"]
# 朝向
orientation = ["侧向", "正向"]
# 生成所有组合
result = []
# upper、lower、number、three为同类型,只能选一个,格式 [upper, lower, number, three]_color_orientation
for a in [upper, lower, number, three]:
for b in a:
for d in orientation:
result.append(f"{b}_{d}")
# 结果数量
print(len(result))
print(result)
# 写入文件
with open("classes.txt", "w", encoding="utf-8") as f:
for line in result:
f.write(line + "\n")
结果如下
4 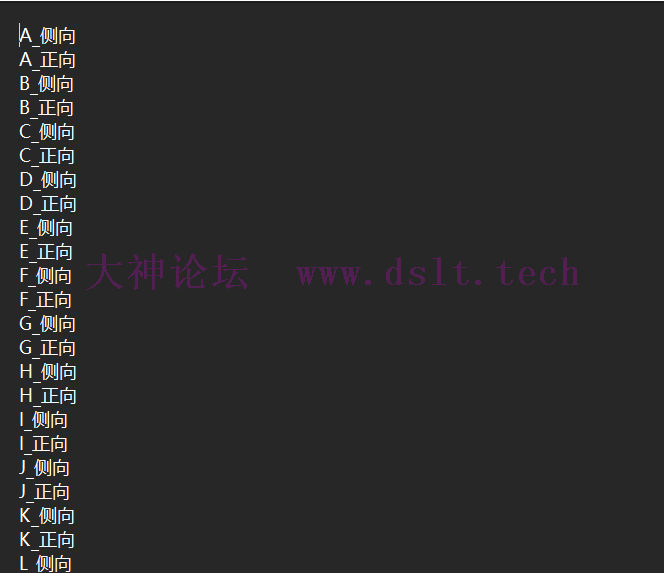
将该文件命名为classes.txt,随后我们可以使用该文件作为labelimg标注工具的预设标签
接下来是图片的处理,我们将800张图片(更多类型以此类推)以下面的数量分割 100 150 250 300...
这样我们可以先标注前100张图片,训练出模型后,使用该模型来标注后面150张图片,然后人工来查找并修正错误,然后将该150张图片和前面100张合并,做增量训练(以此类推)。这样可以大大减少我们的工作量。 验证码标注标记工具准备
先安装labelimg工具 pip install labelimg
进入存放图片的上级目录,然后再输入以下命令启动 labelimg ./images ./classes.txt
其中./images是存放图片的路径,./classes.txt是预设标签文件。 当进入工具界面后,我们在改目录创建labels目录并更改保存标签的位置到改目录。
接下来就是无聊的打标环节
5 
标记完成后的标签目录 
数据集切分这个随便写个代码分割就行,比例大概是 训练集:验证集 = 8:2
├─images
│ ├─train
│ │ 003989b00a7b46514b65ad91e48a7309.jpg
│ │ 0058942dc80284a0121dd83e8af15039.jpg
│ │ ...
│ │
│ └─val
│ 9cbb49f0aa05f503f56938bd07609f19.jpg
│ 9d59c47b4bb9345753effdf9b7250c18.jpg
│ ...
│
└─labels
│
├─train
│ 003989b00a7b46514b65ad91e48a7309.txt
│ 0058942dc80284a0121dd83e8af15039.txt
│ ...
│
└─val
003989b00a7b46514b65ad91e48a7309.txt
0058942dc80284a0121dd83e8af15039.txt
...
模型训练yolov5识别目标位置和方向yolo是一款强大的目标检测算法,对此网上的教程很多了,我只说一下相关配置。 https://github.com/ultralytics/yolov5 配置文件准备我们在data目录下创建config.yml文件,上面填写你的数据集目录,并将classes.txt类型填上去。 path: dataset # 数据集目录(可以用绝对路径)
train: images/train # 训练图像目录(相对于path)
val: images/val # 验证图像目录(相对于path)
test: # test images (optional)
# 种类个数
nc: 132
# 种类名称列表
names: [ "A_侧向", "A_正向", "B_侧向", "B_正向", "C_侧向", "C_正向", "D_侧向", "D_正向", "E_侧向", "E_正向", "F_侧向", "F_正向", "G_侧向", "G_正向", "H_侧向", "H_正向", "I_侧向", "I_正向", "J_侧向", "J_正向", "K_侧向", "K_正向", "L_侧向", "L_正向", "M_侧向", "M_正向", "N_侧向", "N_正向", "O_侧向", "O_正向", "P_侧向", "P_正向", "Q_侧向", "Q_正向", "R_侧向", "R_正向", "S_侧向", "S_正向", "T_侧向", "T_正向", "U_侧向", "U_正向", "V_侧向", "V_正向", "W_侧向", "W_正向", "X_侧向", "X_正向", "Y_侧向", "Y_正向", "Z_侧向", "Z_正向", "a_侧向", "a_正向", "b_侧向", "b_正向", "c_侧向", "c_正向", "d_侧向", "d_正向", "e_侧向", "e_正向", "f_侧向", "f_正向", "g_侧向", "g_正向", "h_侧向", "h_正向", "i_侧向", "i_正向", "j_侧向", "j_正向", "k_侧向", "k_正向", "l_侧向", "l_正向", "m_侧向", "m_正向", "n_侧向", "n_正向", "o_侧向", "o_正向", "p_侧向", "p_正向", "q_侧向", "q_正向", "r_侧向", "r_正向", "s_侧向", "s_正向", "t_侧向", "t_正向", "u_侧向", "u_正向", "v_侧向", "v_正向", "w_侧向", "w_正向", "x_侧向", "x_正向", "y_侧向", "y_正向", "z_侧向", "z_正向", "0_侧向", "0_正向", "1_侧向", "1_正向", "2_侧向", "2_正向", "3_侧向", "3_正向", "4_侧向", "4_正向", "5_侧向", "5_正向", "6_侧向", "6_正向", "7_侧向", "7_正向", "8_侧向", "8_正向", "9_侧向", "9_正向", "圆柱_侧向", "圆柱_正向", "圆锥_侧向", "圆锥_正向", "球_侧向", "球_正向", "立方体_侧向", "立方体_正向" ]
下载预训练权重https://github.com/ultralytics/yolov5/releases/tag/v7.0 选择你的预训练权重大小,推荐s和m大小的权重。
将下载好的预训练权重放入你的yolo文件夹 开始训练方便起见我们在train.py同一目录创建train2.py文件 from yolov5.train import run
# 配置文件路径
CONFIG_PATH = r"yolov5\data\config.yaml"
# 权重文件路径
WEIGHTS_PATH = r"yolov5\yolov5m.pt"
# 运行结果保存路径
OUTPUT = r"output\train"
# 运行代码的硬件 (0,1,2...,cpu)
DEVICE = "0"
if __name__ == "__main__":
run(
data=CONFIG_PATH,
weights=WEIGHTS_PATH,
project=OUTPUT,
device=DEVICE,
num_workers=2,
batch_size=8
)
我们输入以下命令开始训练 python train2.py
训练结果
7 
8 
图片预测我们可以使用detect.py推理图片,加上--save-txt可以保存标签文件。 注: 预测的图片不能是数据集的图片
python detect.py --weights [训练好的权重文件] --source [需要预测的图片目录] --data [配置文件data.yml路径] --save-txt
等待预测结束后可以查看预测结果。
9 
增量训练如果不太理想可以使用导出的标签文件重新标注,标注完成后将新的数据集合并到旧的数据集上。
权重选择上一次训练好的权重,然后重复训练步骤,直到模型达到你的预期为止。 AlexNet做颜色分类模型和训练代码可以参考这篇文章 https://blog.csdn.net/weixin_45930948/article/details/120104737 数据集准备我们使用yolo中推理代码来切割图片,加上--save-crop即可 python detect.py --weights [训练好的权重文件] --source [需要预测的图片目录] --data [配置文件data.yml路径] --save-crop
10 
然后用你自己喜欢的方式将图片分成5种颜色,然后放入对应文件夹。 ├─blue
│ 00032a30a25473496c51e5a6c3573dd9.jpg
│ ...
│
├─gray
│ 007733e2d23b38498b0194022edd344f.jpg
│ ...
│
├─green
│ 00c1c547043f1356fd19b311eaba0f5c.jpg
│ ...
│
├─red
│ 00d3b162c2f3ee9a304ad586aa06f652.jpg
│ ...
│
└─yellow
001d46958fb2fccc05c89e336bc36dac.jpg
...
代码处理可以在训练和预测代码中把图片处理的归一化去除,因为后期导出onnx后没必要归一化处理图片。
11 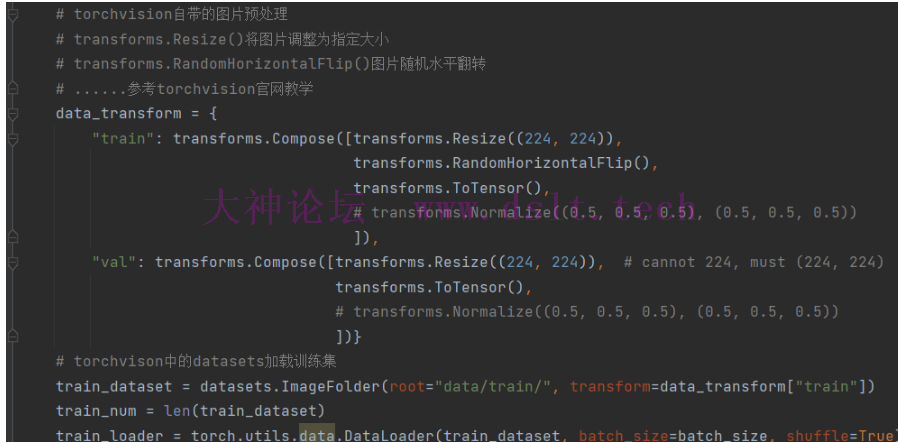
并且将num_classes的值该为5,因为只需要识别5种颜色 训练模型运行训练代码。
12 
可以看到经过不到10轮训练,正确率已经接近1了,训练结束后选择正确率最高的模型进行预测。
这时可以运行预测代码查看训练结果
13 
图片识别导出onnx模型yolov5导出yolo提供功能齐全的导出代码,我们在export.py中修改模型路径、配置文件和导出的模型格式,运行后会在权重目录下生成同名的onnx模型。 AlexNet导出在模型目录新建export.py import torch
from model import AlexNet
out_onnx = 'model.onnx'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dummy = torch.randn(1, 3, 224, 224, dtype=torch.float32).to(device)
model = AlexNet(num_classes=5).to(device)
model.load_state_dict(torch.load("./你需要转换的模型路径"))
model.eval()
torch.onnx.export(model, dummy, out_onnx, verbose=True, input_names=["input"])
print("finish!")
运行后即可导出onnx模型 图片预处理和结果处理仅展示颜色分类模型的onnx使用,yolo请自行百度。 注:yolo onnx模型也需要classes列表。
图片预处理由于onnx模型需要使用np格式的图片,并且要求的图片维度为(1, 3, w, h)(可在导出里修改)所以我们需要使用cv2处理图片。 import cv2
import numpy as np
image = "图片路径"
img = cv2.imread(image)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224)).astype(np.float32) / 255
img = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
# img处理后直接输入进onnx
注意的是,PIL类型的图片不能直接使用np.array()来转换图片,否则会影响图片预测结果,可以将PIL保存为二进制图片,再使用cv2读取。 结果处理由于没有softmax函数所以我们自己写一个。 def softmax(x):
"""np实现torch.softmax"""
e_x = np.exp(x - np.max(x))
return e_x / np.sum(e_x)
完整的结果处理 import io
import cv2
import os
import numpy as np
import onnxruntime
from PIL import Image
class ColorClassify(object):
def __init__(self, color_model_path):
self.color_list = ["blue", "gray", "green", "red", "yellow"]
if not os.path.exists(color_model_path):
raise FileNotFoundError(f"Error! 模型路径无效: '{color_model_path}'")
self._session = onnxruntime.InferenceSession(color_model_path)
@staticmethod
def softmax(x):
"""np实现torch.softmax"""
e_x = np.exp(x - np.max(x))
return e_x / np.sum(e_x)
@staticmethod
def read_img(image):
"""
转换图片格式、形状(1,3,244,244)
注意! 不能直接使用np.array来转换Image图片! 否则输出结果不正确
"""
if isinstance(image, np.ndarray):
img = image
elif isinstance(image, bytes):
img = cv2.imdecode(np.array(bytearray(image), dtype='uint8'), cv2.IMREAD_COLOR)
elif isinstance(image, Image.Image):
buf = io.BytesIO()
image.save(buf, format="PNG")
img = cv2.imdecode(np.array(bytearray(buf.getvalue()), dtype='uint8'), cv2.IMREAD_COLOR)
elif isinstance(image, str):
img = cv2.imread(image)
else:
raise ValueError(f"Error! 不支持的图片格式: {type(image)}")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (224, 224)).astype(np.float32) / 255
img = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
return img
def predict(self, image):
img = self.read_img(image)
result = self._session.run(None, {"input": img})
output = self.softmax(result[0][0])
# 最大值(置信度)
# predict_cla = max(output)
# 最大值索引
index = np.argmax(output)
return self.color_list[index]
if __name__ == "__main__":
cc = ColorClassify("model.onnx")
result = cc.predict("B.jpg")
print("预测结果: %s" % result)
# > 预测结果: blue
2种模型结合- 1.两种模型结合很简单,先使用yolov5进行模板检测,根据返回的坐标把图片切割下来,并保存改图片对应的标签
- 2.在使用颜色分类模型对每种标签进行颜色分类,将识别到的颜色添加到对应标签上
- 3.输出图像查看结果
颜色分类前:
14 
颜色分类后: 
提示词推理3种提示类型查看大量提示词后能发型一个规律,提示词主要有3种类型: - 请点击[目标]
- 请点击[参照物]朝向一样的[目标]
- 请点击[参照物]颜色一样的[目标]
而目标或参照物可具体分为:特征+物体或是单个物体 特征为颜色或朝向,并且二者不会同时出现,而大小写和数字我们已经区分好了,不属于特征。 所以特征一共3种: 整理完成后推理就相对简单了。 相同形状物体的处理识别到相同物体的结果可能会出现以下情况: - c和C
- I(大小i)和l(小写L)
- k和K
- o、O和0
- s和S
- v和V
- w和W
- x和X
- z和Z
如果第一次查找图片中的物体没有查找到,那么可以将目标物体替换为相同形状的物体重新查找,直到查找到为止。 识别结果最终达到了80%左右的正确率 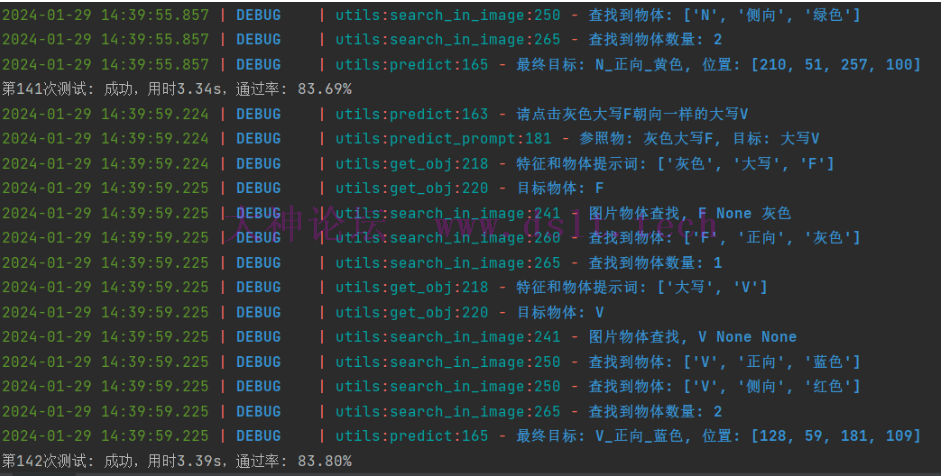
可能是我推理代码写得不够好或是模型不够好,欢迎大佬指教。
注:若转载请注明大神论坛来源(本贴地址)与作者信息。
|


 发表于 2024-01-30 21:55
发表于 2024-01-30 21:55





 评分
评分 顶
顶 踩
踩 扫码赞助
扫码赞助